1.PersistentVolume (PV)
|
1 2 3 4 |
PV是由管理员设置的存储,它是k8s群集的一部分。就像节点是集群中的资源一样,PV 也是集群中的资源。 PV 是 Volume 之类的卷插件,但具有独立于使用 PV 的 Pod 的生命周期。也就是说pv是由k8s管理员创建的,大大小小的存储仓, 然后各个pod可以来匹配使用,他完全独立于pod之外,由每个pod的pvc来调用。所以无论你的pod是死是活,重新部署或者怎样,丝毫不会影响pv存储仓内已经存储完成的数据。 另外此API也可以使用外部存储,如NFS,iSCSI 或特定于云供应商的存储系统 |
创建pv前,请先创建其使用的外部持久化存储设备,当前pv支持的外volume插件有
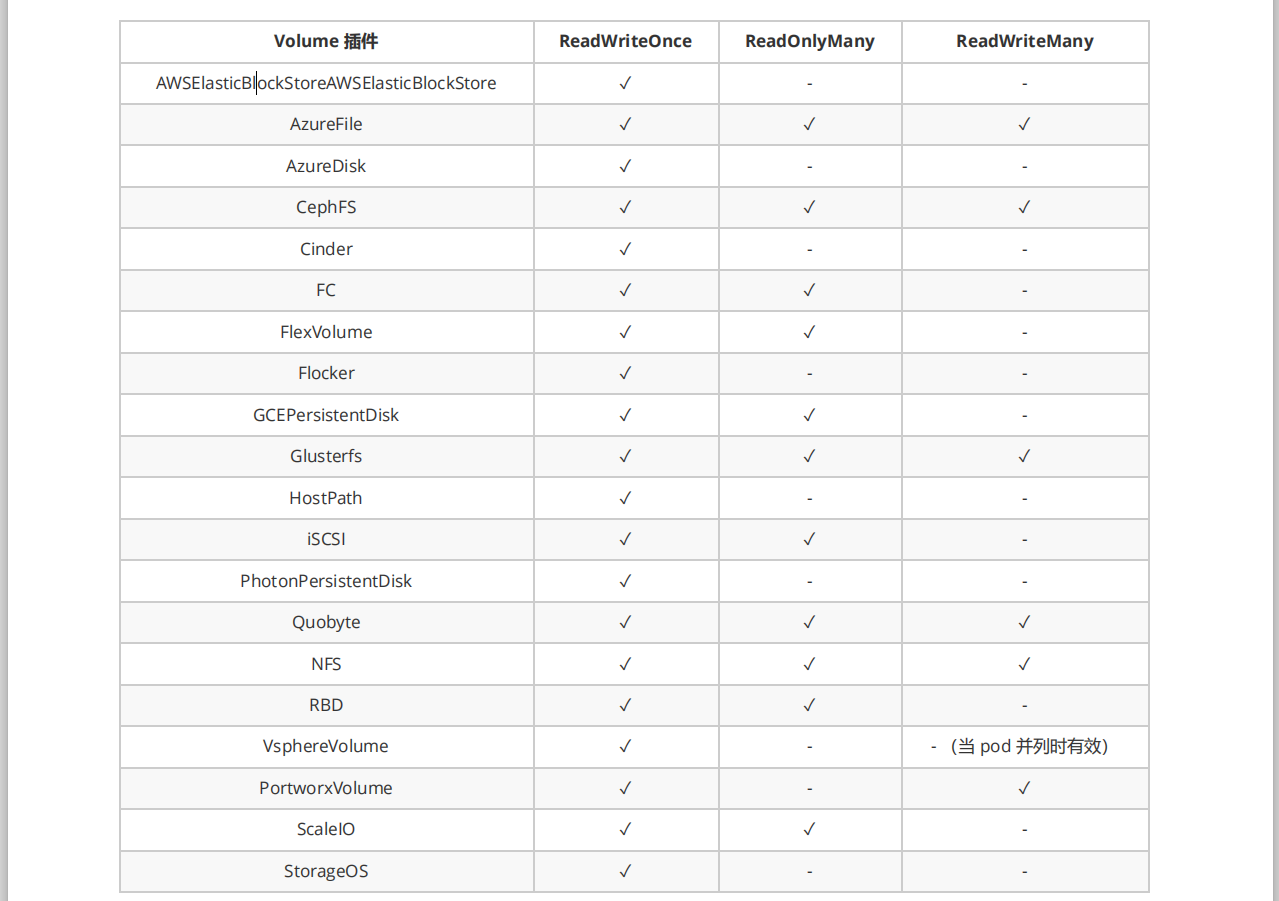
PV 访问模式
PersistentVolume 可以以资源提供者支持的任何方式挂载到主机上。如下表所示,供应商具有不同的功能,每个 PV 的访问模式都将被设置为该卷支持的特定模式。例如,NFS 可以支持多个读/写客户端,但特定的 NFS PV 可能 以只读方式导出到服务器上。每个 PV 都有一套自己的用来描述特定功能的访问模式
- ReadWriteOnce——该卷可以被单个节点以读/写模式挂载
- ReadOnlyMany——该卷可以被多个节点以只读模式挂载
- ReadWriteMany——该卷可以被多个节点以读/写模式挂载
在命令行中,访问模式缩写为:
- RWO – ReadWriteOnce
- ROX – ReadOnlyMany
- RWX – ReadWriteMany

pv的回收策略
- Retain(保留)——手动回收
- Recycle(回收)——基本擦除( rm -rf /thevolume/* ) (已废弃)
- Delete(删除) ——关联的存储资产(例如 AWS EBS、GCE PD、Azure Disk 和 OpenStack Cinder 卷)将被删除
当前,只有 NFS 和 HostPath 支持回收策略。AWS EBS、GCE PD、Azure Disk 和 Cinder 卷支持删除策略
PV状态
- Available(可用)——一块空闲资源还没有被任何声明绑定
- Bound(已绑定)——卷已经被声明绑定
- Released(已释放)——声明被删除,但是资源还未被集群重新声明
- Failed(失败)——该卷的自动回收失败

命令行会显示绑定到 PV 的 PVC 的名称
持久化演示说明 – NFS
1.安装nfs(每个节点都要安装)
|
1 2 3 4 5 6 7 8 9 10 |
yum install -y nfs-common nfs-utils rpcbind mkdir /nfsdata chmod 666 /nfsdata chown nfsnobody /nfsdata cat /etc/exports /nfsdata *(rw,no_root_squash,no_all_squash,sync) systemctl start rpcbind systemctl start nfs #并且在每个节点都要创建pv对应的挂载文件夹(因为随机分散的节点容器都会挂载) mkidr -p /nfs/pv{1..4} |
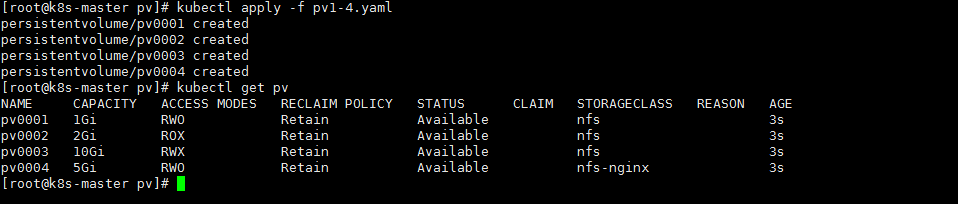
2.部署创建pv(创建多个)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
apiVersion: v1 kind: PersistentVolume #类型 metadata: name: pv0001 spec: capacity: storage: 1Gi #声明卷大小为5G volumeMode: Filesystem accessModes: - ReadWriteOnce #只允许一个节点人读写 persistentVolumeReclaimPolicy: Retain #回收策略 storageClassName: nfs #存储类名称 ,可以理解为,某些pv为一类,自然他也有命名空间,上头来请求的时候通过类名来区分 nfs: path: /nfs/pv1 #挂载到的目录 server: 192.168.6.189 #nfs机器ip --- apiVersion: v1 kind: PersistentVolume metadata: name: pv0002 spec: capacity: storage: 2Gi volumeMode: Filesystem accessModes: - ReadOnlyMany persistentVolumeReclaimPolicy: Retain storageClassName: nfs nfs: path: /nfs/pv2 server: 192.168.6.189 --- apiVersion: v1 kind: PersistentVolume metadata: name: pv0003 spec: capacity: storage: 10Gi volumeMode: Filesystem accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Retain storageClassName: nfs nfs: path: /nfs/pv3 server: 192.168.6.189 --- apiVersion: v1 kind: PersistentVolume metadata: name: pv0004 spec: capacity: storage: 5Gi volumeMode: Filesystem accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Retain storageClassName: nfs-nginx nfs: path: /nfs/pv4 server: 192.168.6.189 |
创建服务并使用 PVC(pvc简单来说就是,匹配pv的一些属性准则)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
apiVersion: v1 kind: Service metadata: name: nginx labels: app: nginx spec: ports: - port: 80 name: web clusterIP: None selector: #选择器查找nginx标签的pod,为之提供服务 app: nginx --- apiVersion: apps/v1 kind: StatefulSet #创建有状态服务 metadata: name: web spec: selector: matchLabels: app: nginx serviceName: "nginx" replicas: 2 template: metadata: labels: app: nginx spec: containers: - name: nginx image: hub.atshooter.com/k8s/nginx:v1.0 ports: - containerPort: 80 name: web volumeMounts: - name: www mountPath: /usr/share/nginx/html volumeClaimTemplates: - metadata: name: www spec: accessModes: [ "ReadWriteOnce" ] #这里对应pv上的访问模式 storageClassName: "nfs" #pv的命名空间 resources: requests: storage: 1Gi |
当前我们创建的PVC会去pv资源点里首先查找 命名空间 为 nfs 的 pv 集合,然后匹配访问模式为 ReadWriteOnce 的pv ,然后 匹配存储空间大小,大于或者等于1G的pv,来作为vloume对nginx进行挂载,我们有2个副本,所以也应当有2个对应的pv被绑定。
挂载目录为:将匹配的pv的目录挂载到nginx容器的/usr/share/nginx/html目录位置,用来作为nginx的web存储目录。
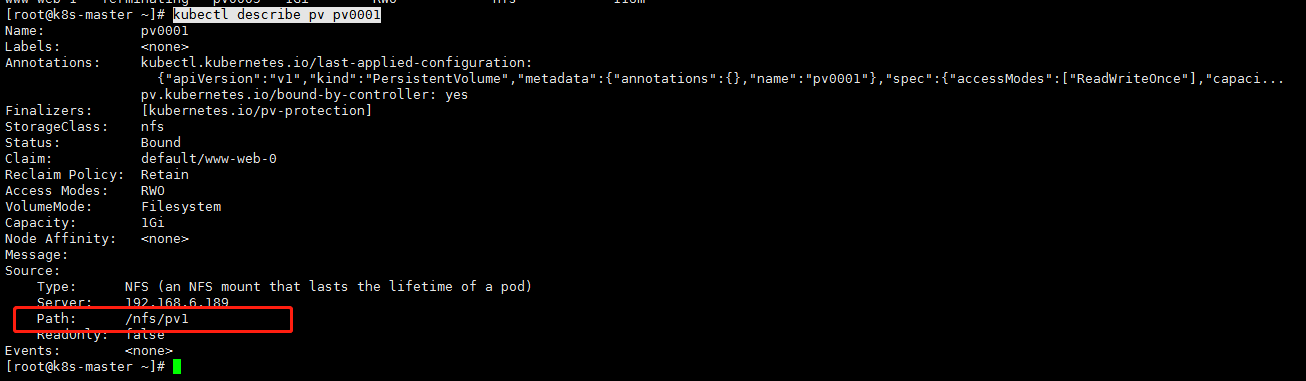
查看pvc 与 pv


查看pv绑定到了哪个目录
|
1 |
kubectl describe pv pv0001 |
下来验证下是否挂载成功了
在nfs机器的pv1目录里新建个文件

登录web-0容器查看
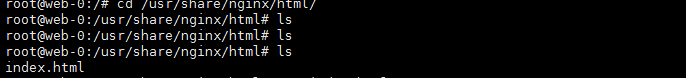
说明挂载没问题
下来我们访问下web-0

关于 StatefulSet
关于statefulset深入理解,这里有个大佬写的很好,传送门
- statefulset匹配 Pod name ( 网络标识 ) 的模式为:$(statefulset名称)-$(序号),比如上面:web-0 web-1
- StatefulSet为每个 Pod 副本创建了一个 DNS 域名,这个域名的格式为: $(podname).(headless servername),也就意味着服务间是通过Pod域名来通信而非 Pod IP,因为当Pod所在Node发生故障时, Pod 会被飘移到其它 Node 上,Pod IP 会发生变化,但是 Pod 域名不会有变化 例如:ping web-0.nginx
- StatefulSet 使用 Headless 服务来控制 Pod 的域名,这个域名的 FQDN 为:$(servicename).$(namespace).svc.cluster.local(无头符),其中,”cluster.local” 指的是集群的域名 例:dig -t A nginx.default. svc.cluster.local @coreDns ip
- 根据 volumeClaimTemplates,为每个 Pod 创建一个 pvc,pvc 的命名规则匹配模式:(volumeClaimTemplates.name)-(pod_name),比如上面的 volumeMounts.name=www, Podname=web-[0-2],因此创建出来的 PVC 是 www-web-0、www-web-1、www-web-2

另外删除 Pod 不会删除其 pvc,手动删除 pvc 将自动释放 pv
删除pod
|
1 |
kubectl delete statefulset --all #删除所有pod |
删除svc 和 pvc
|
1 2 |
kubectl delete svc --all kubectl delete pvc --all |
查看pv

看到没,他已经开始回收数据了
手动帮他回收
|
1 2 |
kubectl edit pv [pvName] kubectl edit pv pv0001 |
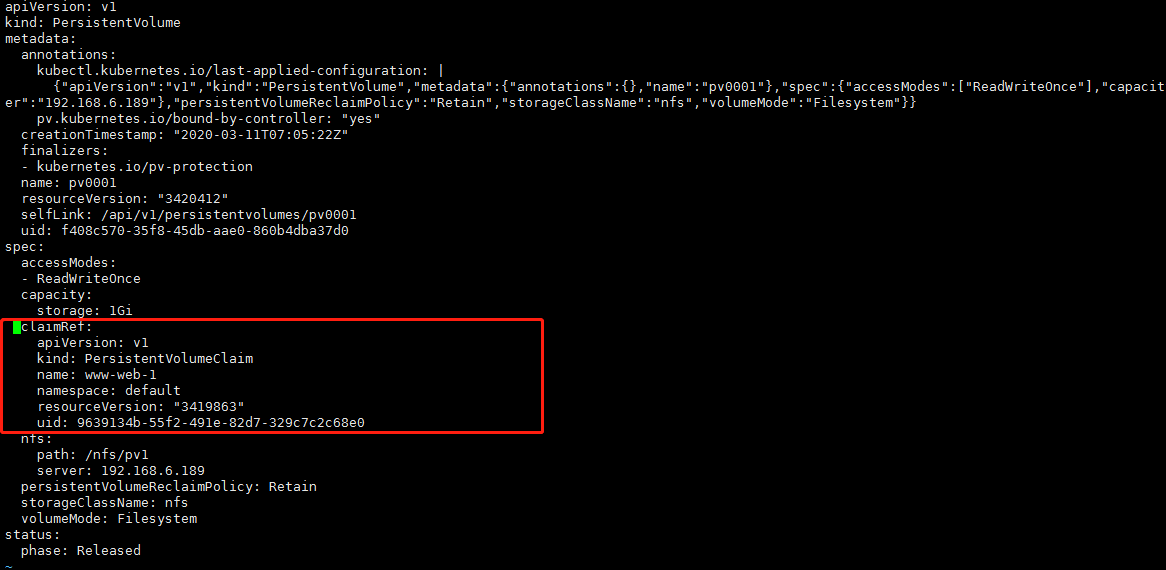

注意:如果你没有手动帮他回收,他的状态一直是Released回收状态,这个时候你再重新应用yaml文件,pod一直会显示pending状态,因为你没有释放,当前pv一直被上一次的pod占用。新的pod接入不进来。就会卡着。提示错误是找不到挂载的pv类型。只有当pv状态为可用Released,新的pod才会匹配成功
Statefulset的启停顺序:
- 有序部署:部署StatefulSet时,如果有多个Pod副本,它们会被顺序地创建(从0到N-1)并且,在下一个 Pod运行之前所有之前的Pod必须都是Running和Ready状态。
- 有序删除:当Pod被删除时,它们被终止的顺序是从N-1到0。
- 有序扩展:当对Pod执行扩展操作时,与部署一样,它前面的Pod必须都处于Running和Ready状态。
StatefulSet使用场景:
- 稳定的持久化存储,即Pod重新调度后还是能访问到相同的持久化数据,基于 PVC 来实现
- 稳定的网络标识符,即 Pod 重新调度后其 PodName 和 HostName 不变。
- 有序部署,有序扩展,基于 init containers 来实现。
- 有序收缩。
回顾创建的整个流程(重要)
|
1 2 3 4 5 |
首先,StatefulSet的控制器直接管理的是Pod,而StatefulSet区分这些实例的方式,就是通过在Pod的名字里面加上事先约定好的编号. 其次,Kubernetes通过Headless Service,为这些有编号的Pod,在DNS服务器中生成带有同样编号的DNS记录.只要StatefulSet能够保证这些Pod名字里的编号不变,那么Service中DNS记录也就不会变. 最后,StatefulSet还为每一个Pod分配并创建一个同样编号的PVC.这样就可以保证每个Pod都拥有一个独立的Volume.在这种情况下,即使Pod被删除,它所对应的PVC和PV依然会留下来,所以当这个Pod被重新创建出来之后,Kubernetes会为它找到同样编号的PVC,挂载这个PVC对应的Volume,从而获取到以前保存在Volume中的数据. 其实StatefulSet就是一种特殊的Deployment,只不过它的每个Pod都被编号了.正是由于这种机制,使得具有主从关系的创建成为可能. |
下面是个人根据理解,画出的pv和pvc的工作图(如有不正确之处,还请指正)
- 本文固定链接: https://www.yoyoask.com/?p=2304
- 转载请注明: shooter 于 SHOOTER 发表