1. 什么是docker swarm?
|
1 2 3 4 5 |
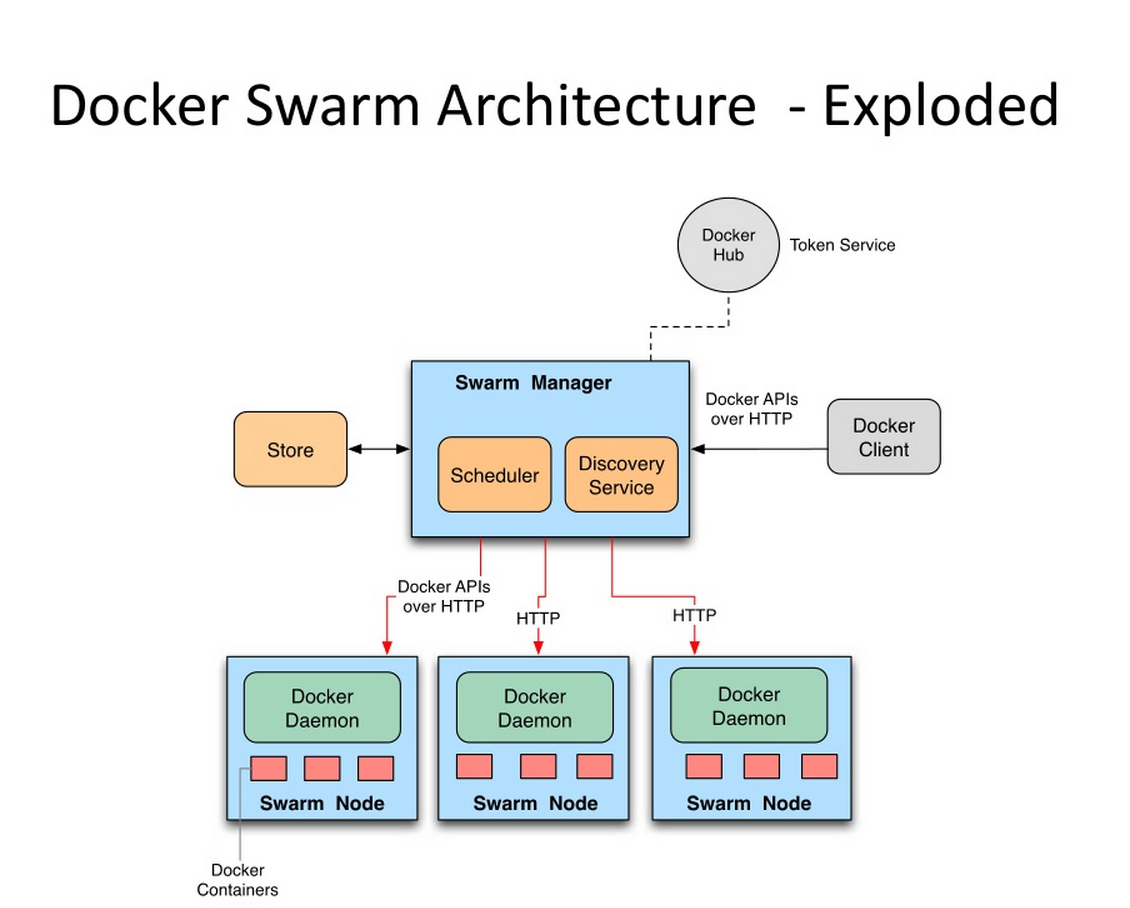
Swarm 在 Docker 1.12 版本之前属于一个独立的项目,在 Docker 1.12 版本发布之后,该项目合并到了 Docker 中,成为 Docker 的一个子命令。目前,Swarm 是 Docker 社区提供的唯一一个原生支持 Docker 集群管理的工具。它可以把多个 Docker 主机组成的系统转换为单一的虚拟 Docker 主机,使得容器可以组成跨主机的子网网络。 Docker Swarm 是一个为 IT 运维团队提供集群和调度能力的编排工具。用户可以把集群中所有 Docker Engine 整合进一个「虚拟 Engine」的资源池,通过执行命令与单一的主 Swarm 进行沟通,而不必分别和每个 Docker Engine 沟通。在灵活的调度策略下,IT 团队可以更好地管理可用的主机资源,保证应用容器的高效运行。 Swarm的基本架构如下图所示: |
2. Docker Swarm 优点
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
任何规模都有高性能表现 对于企业级的 Docker Engine 集群和容器调度而言,可拓展性是关键。任何规模的公司——不论是拥有五个还是上千个服务器——都能在其环境下有效使用 Swarm。 经过测试,Swarm 可拓展性的极限是在 1000 个节点上运行 50000 个部署容器,每个容器的启动时间为亚秒级,同时性能无减损。 灵活的容器调度 Swarm 帮助 IT 运维团队在有限条件下将性能表现和资源利用最优化。Swarm 的内置调度器(scheduler)支持多种过滤器,包括:节点标签,亲和性和多种容器部策略如 binpack、spread、random 等等。 服务的持续可用性 Docker Swarm 由 Swarm Manager 提供高可用性,通过创建多个 Swarm master 节点和制定主 master 节点宕机时的备选策略。如果一个 master 节点宕机,那么一个 slave 节点就会被升格为 master 节点,直到原来的 master 节点恢复正常。 此外,如果某个节点无法加入集群,Swarm 会继续尝试加入,并提供错误警报和日志。在节点出错时,Swarm 现在可以尝试把容器重新调度到正常的节点上去。 和 Docker API 及整合支持的兼容性 Swarm 对 Docker API 完全支持,这意味着它能为使用不同 Docker 工具(如 Docker CLI,Compose,Trusted Registry,Hub 和 UCP)的用户提供无缝衔接的使用体验。 Docker Swarm 为 Docker 化应用的核心功能(诸如多主机网络和存储卷管理)提供原生支持 开发的 Compose 文件能(通过 docker-compose up )轻易地部署到测试服务器或 Swarm 集群上。Docker Swarm 还可以从 Docker Trusted Registry 或 Hub 里 pull 并 run 镜像。 |
相关概念
1. 节点
|
1 2 3 4 5 6 7 8 9 10 |
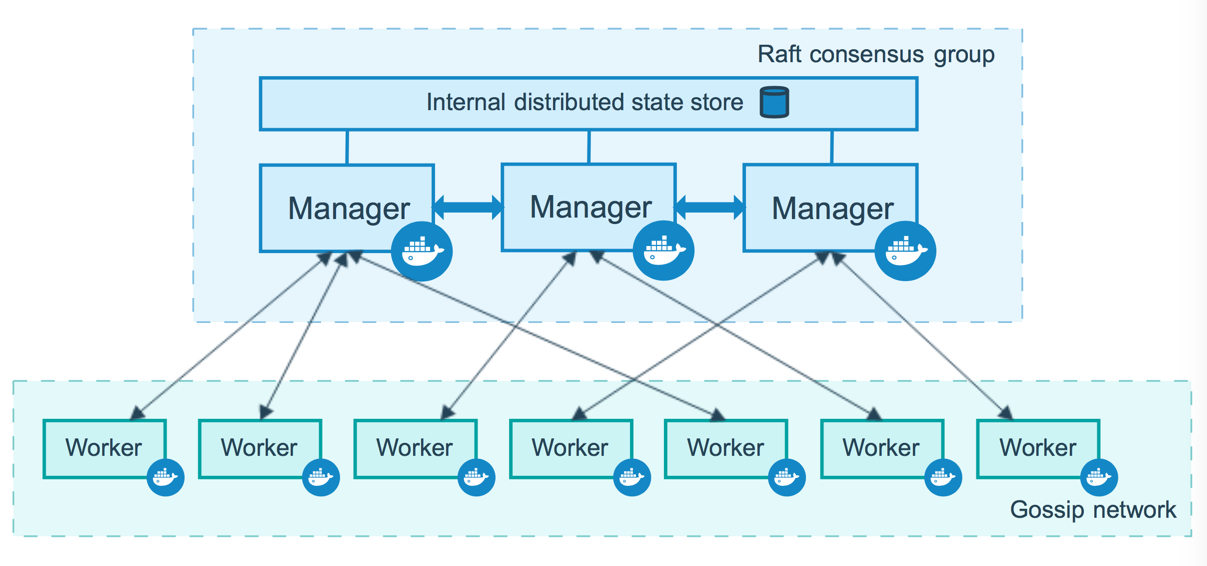
有两种类型的节点: managers 和 workers. 管理节点(managers) 管理节点用于 Swarm 集群的管理,docker swarm 命令基本只能在管理节点执行(节点退出集群命令 docker swarm leave 可以在工作节点执行)。一个 Swarm 集群可以有多个管理节点,但只有一个管理节点可以成为 leader,leader 通过 raft 协议实现。 为了利用swarm模式的容错功能,Docker建议您根据组织的高可用性要求实现奇数个节点。当您拥有多个管理器时,您可以从管理器节点的故障中恢复而无需停机。 N个管理节点的集群容忍最多损失 (N-1)/2 个管理节点。 Docker建议一个集群最多7个管理器节点。 重要说明:添加更多管理节点并不意味着可扩展性更高或性能更高。一般而言,情况正好相反。 |
工作节点(workers)
工作节点是任务执行节点,管理节点将服务 (service) 下发至工作节点执行。管理节点默认也作为工作节点。你也可以通过配置让服务只运行在管理节点。下图展示了集群中管理节点与工作节点的关系。
2. 服务和任务
|
1 2 |
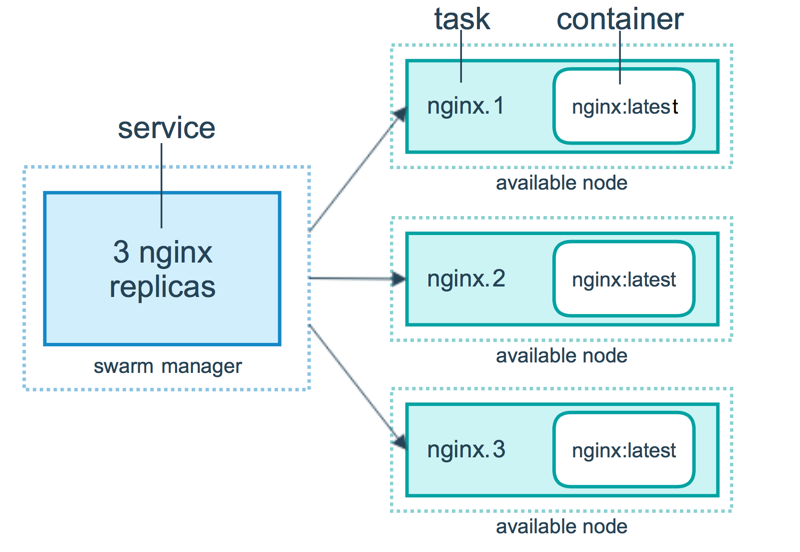
任务 (Task)是 Swarm 中的最小的调度单位,目前来说就是一个单一的容器。 服务 (Services) 是指一组任务的集合,服务定义了任务的属性。服务有两种模式: |
- replicated services (复制服务)按照一定规则在各个工作节点上运行指定个数的任务。
- global services (全局服务)每个工作节点上运行一个任务。
两种模式通过 docker service create 的 –mode 参数指定。下图展示了容器、任务、服务的关系。
三、Swarm 集群
准备工作:

|
1 |
在主机之间打开端口(2377、7946、4789),或者直接关闭防火墙,关闭selinux |
前期准备:
|
1 2 3 4 5 6 7 8 9 10 11 |
查看防火墙状态 firewall-cmd --state 停止firewall systemctl stop firewalld.service 禁止firewall开机启动 systemctl disable firewalld.service |
关闭selinux
|
1 2 3 4 5 |
进入到/etc/selinux/config文件 vi /etc/selinux/config 将SELINUX=enforcing改为SELINUX=disabled |
设置系统主机名以及 Host 文件的相互解析
|
1 2 3 |
master执行:hostnamectl set-hostname swarm-master node1执行:hostnamectl set-hostname swarm-node1 node2执行:hostnamectl set-hostname swarm-node2 |
设置hosts文件相互解析(三台都要设置)
|
1 2 3 |
192.168.66.40 swarm-master 192.168.66.41 swarm-node1 192.168.66.43 swarm-node2 |
1.docker安装 传送门 (三台都要安装)
2. 初始化swarm
把第一台机器swarm-master充当管理节点,第二台swarm-node1 、第三台swarm-node2作为工作节点。
|
1 2 3 4 5 6 7 8 9 10 11 |
初始化swarm 在master节点执行:docker swarm init --advertise-addr 192.168.66.40 [root@localhost ~]# docker swarm init --advertise-addr 192.168.66.40 Swarm initialized: current node (8d56ymnmgog0rwbv877rizgw5) is now a manager. To add a worker to this swarm, run the following command: docker swarm join --token SWMTKN-1-36sa12dkjoroyoxr195y9gfsaap5xcy5rg2xlu6v7gqcmiczph-5fcg8z3rb71737yzj7c8rwk44 192.168.66.40:2377 To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions. |
上面输出的这一段就是其他工作节点加入集群的命令:
|
1 2 3 4 5 |
docker swarm join --token SWMTKN-1-36sa12dkjoroyoxr195y9gfsaap5xcy5rg2xlu6v7gqcmiczph-5fcg8z3rb71737yzj7c8rwk44 192.168.66.40:2377 也可以通过命令获取加入命令 docker swarm join-token worker |
如果你的 Docker 主机有多个网卡,拥有多个 IP,必须使用 –advertise-addr 指定 IP。
执行 docker swarm init 命令的节点自动成为管理节点。
命令 docker info 可以查看 swarm 集群状态:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
[root@localhost ~]# docker info Client: Debug Mode: false Server: Containers: 0 Running: 0 Paused: 0 Stopped: 0 Images: 0 Server Version: 19.03.8 Storage Driver: overlay2 Backing Filesystem: <unknown> Supports d_type: true Native Overlay Diff: true Logging Driver: json-file Cgroup Driver: cgroupfs Plugins: Volume: local Network: bridge host ipvlan macvlan null overlay Log: awslogs fluentd gcplogs gelf journald json-file local logentries splunk syslog Swarm: active NodeID: 8d56ymnmgog0rwbv877rizgw5 Is Manager: true ClusterID: or3kumy0f8u3r1efen3zabryn Managers: 1 Nodes: 1 Default Address Pool: 10.0.0.0/8 SubnetSize: 24 Data Path Port: 4789 Orchestration: Task History Retention Limit: 5 Raft: Snapshot Interval: 10000 Number of Old Snapshots to Retain: 0 Heartbeat Tick: 1 Election Tick: 10 Dispatcher: Heartbeat Period: 5 seconds CA Configuration: Expiry Duration: 3 months Force Rotate: 0 Autolock Managers: false Root Rotation In Progress: false Node Address: 192.168.66.40 Manager Addresses: 192.168.66.40:2377 Runtimes: runc Default Runtime: runc Init Binary: docker-init containerd version: 7ad184331fa3e55e52b890ea95e65ba581ae3429 runc version: dc9208a3303feef5b3839f4323d9beb36df0a9dd init version: fec3683 Security Options: seccomp Profile: default Kernel Version: 3.10.0-1062.el7.x86_64 Operating System: CentOS Linux 7 (Core) OSType: linux Architecture: x86_64 CPUs: 4 Total Memory: 1.777GiB Name: localhost.localdomain ID: 6YWZ:ZJLN:VQWN:AYR5:HLE7:EUQZ:YL2D:OJYQ:6QCM:UC33:FAMB:AYJH Docker Root Dir: /var/lib/docker Debug Mode: false Registry: https://index.docker.io/v1/ Labels: Experimental: false Insecure Registries: 127.0.0.0/8 Live Restore Enabled: false |
命令 docker node ls 可以查看集群节点信息:
3. 工作节点加入 swarm 集群
在工作节点执行(注意你的防火墙,最好关掉防火墙)
|
1 |
docker swarm join --token SWMTKN-1-36sa12dkjoroyoxr195y9gfsaap5xcy5rg2xlu6v7gqcmiczph-5fcg8z3rb71737yzj7c8rwk44 192.168.66.40:2377 |

node2,node3都加入集群
在管理节点查看
|
1 |
docker node ls |

为了高可用,我们升级工作节点为管理节点。
|
1 2 |
docker node promote swarm-node1 docker node promote swarm-node2 |
这时我们再看集群的节点信息

|
1 |
swarm-node2、swarm-node3的 集群状态变为 Reachable(选举者),因为集群中节点Leader只能有一个,这个类似zookeeper,只不过zookeepers用的算法是paxos,Swarm用的算法是raft。 |
4. 退出 Swarm 集群
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
1.如果 Manager 想要退出 Swarm 集群, 在 Manager Node 上执行如下命令(主动离开集群,让节点处于down状态,才能删除): docker swarm leave 2.(管理节点,解散集群)如果集群中还存在其它的 Worker Node,还希望 Manager 退出集群,则加上一个强制选项,命令行如下所示: docker swarm leave --force 3.排空节点上的集群容器 。 docker node update --availability drain g36lvv23ypjd8v7ovlst2n3yt 4.删除指定节点 (管理节点上操作) docker node rm g36lvv23ypjd8v7ovlst2n3yt 退出后的节点,依然可以使用 上面的 docker swarm join --token 重新加入集群。 |
集群上部署应用
|
1 2 |
docker service create --replicas 1 --name 别名 镜像ID replicas:指定运行服务的数量.(和k8s需要运行的副本数道理是一样的) |
部署实例:
|
1 2 3 4 5 6 |
#以下命令将nginx容器中的端口80发布到群集中任何节点的端口8080 docker service create \ --name my-web \ --publish published=8080,target=80 \ --replicas 3 \ nginx |
查看集群上的服务
|
1 |
docker service ls |

|
1 2 3 4 5 |
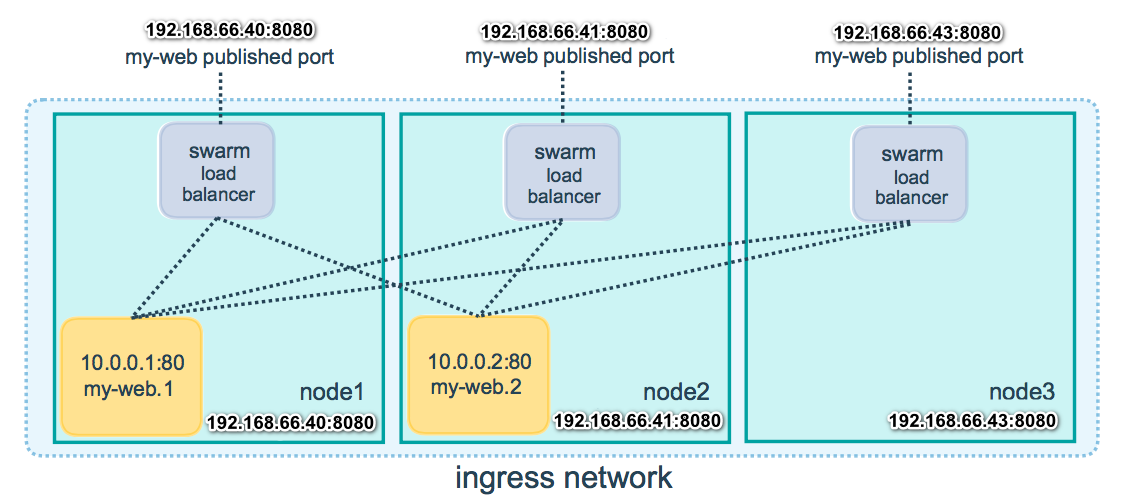
service 通过 ingress load balancing 来发布服务,且 swarm 集群中所有 node 都参与到 ingress 路由网格(ingress routing mesh) 中,访问任意一个 nodeIP+PublishedPort 即可访问到服务。 192.168.66.40:8080 192.168.66.41:8080 192.168.66.43:8080 |
|
1 |
当访问任何节点上的端口8080时,Docker将您的请求路由到活动容器。在群节点本身,端口8080可能并不实际绑定,但路由网格知道如何路由流量,并防止任何端口冲突的发生。 |
|
1 |
所以访问 192.168.66.40:8080、192.168.66.41:8080、192.168.66.43:8080 ,都可以访问到nginx,这样就实现了负载均衡。因为我们指定--replicas 3 启动了3个运行nginx的容器 ,所以三个节点myvm-1、myvm-2、myvm-3 上都运行了一个 nginx 的容器,可以通过改其中一个节点上的nginx的欢迎页 ,然后再访问,来检查是否实现了负载均衡。 |
1.可以通过scale 来指定运行容器的数量。 为服务扩容(缩融)scale
|
1 |
docker service scale my-web=2 |

我通过docker service ls 可以看出 nginx 的副本变成了2个

2.工作节点排除manager,manager只作为管理节点
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
docker node update --availability drain manager # node update : 更改节点状态 # --availability : 三种状态 active: 正常 pause:挂起 drain:排除 1.排除(排除后manager只作为管理节点) docker node update --availability drain swarm-master 2.允许 docker node update –availability active swarm-master |
3.过滤不正常状态
|
1 |
docker service ps -f "desired-state=running" my-web |

排除manager后,其上面运行的服务会转移到其他节点
四、滚动更新服务
例如升级服务的镜像版本
|
1 2 3 4 5 6 7 8 9 10 |
[root@manager ~]# docker service create \ --replicas 3 \ --name redis \ --update-delay 10s \ redis:3.0.6 # 启动3个副本集的redis # update-delay 10s :每个容器依次更新,间隔10s |
滚动更新:
|
1 2 3 |
docker service update --image redis:3.0.7 redis # --image : 指定版本 |
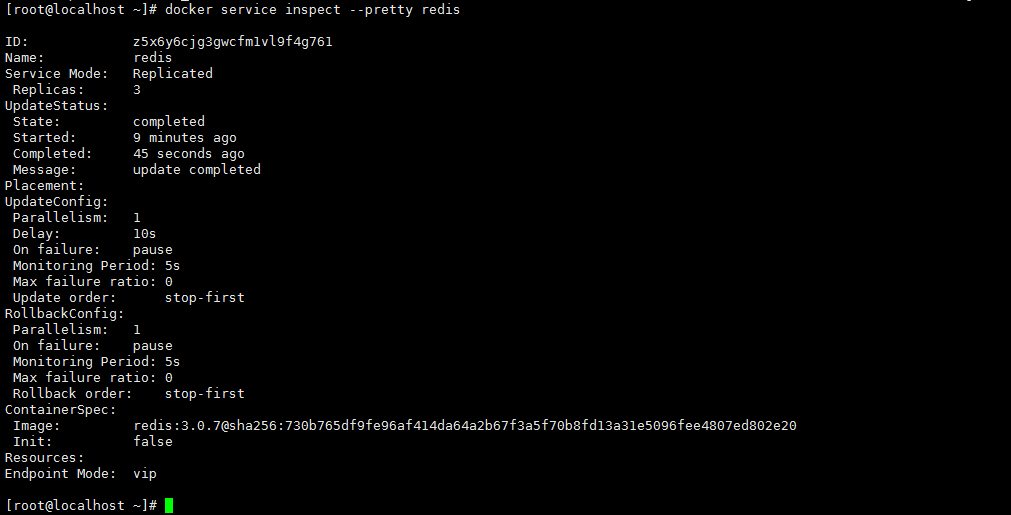
更新完成后新版本和历史记录都能查看

查看配置信息:
|
1 |
docker service inspect --pretty redis |
五、服务更新和回滚策略
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
docker service create \ --name my-web \ --replicas 10 \ --update-delay 10s \ --update-parallelism 2 \ --update-failure-action continue \ --rollback-parallelism 2 \ --rollback-monitor 20s \ --rollback-max-failure-ratio 0.2 \ nginx:1.12.1 # --update-parallelism 2 : 每次允许两个服务一起更新 #--update-failure-action continue : 更新失败后的动作是继续 # --rollback-parallelism 2 : 回滚时允许两个一起 # --rollback-monitor 20s :回滚监控时间20s # --rollback-max-failure-ratio 0.2 : 回滚失败率20% |
如果执行后查看状态不是设置的,可以在update一下,将服务状态设置为自己想要的
|
1 2 3 4 5 |
docker service update --rollback-monitor 20s my-web docker service update --rollback-max-failure-ratio 0.2 my-web # 有两个地方设置数值没有成功,手动设置 |
查看状态:
|
1 |
docker service inspect --pretty my-web |
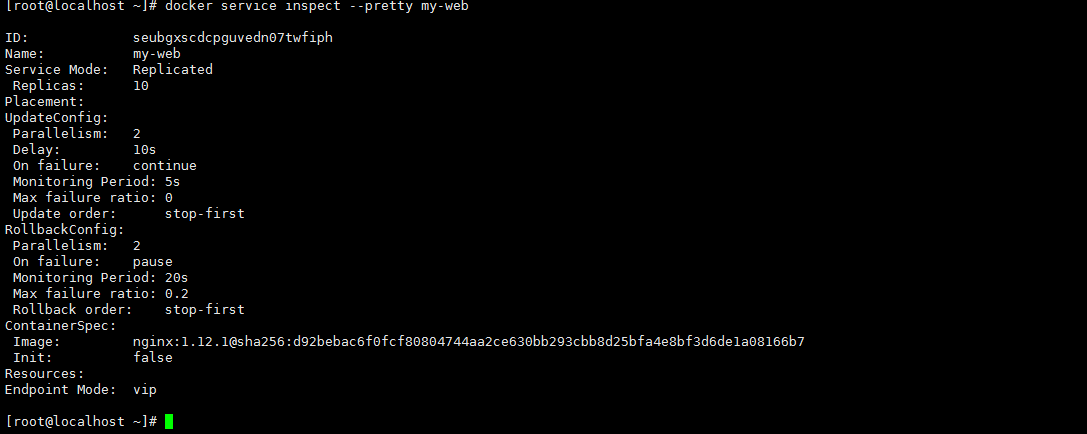
|
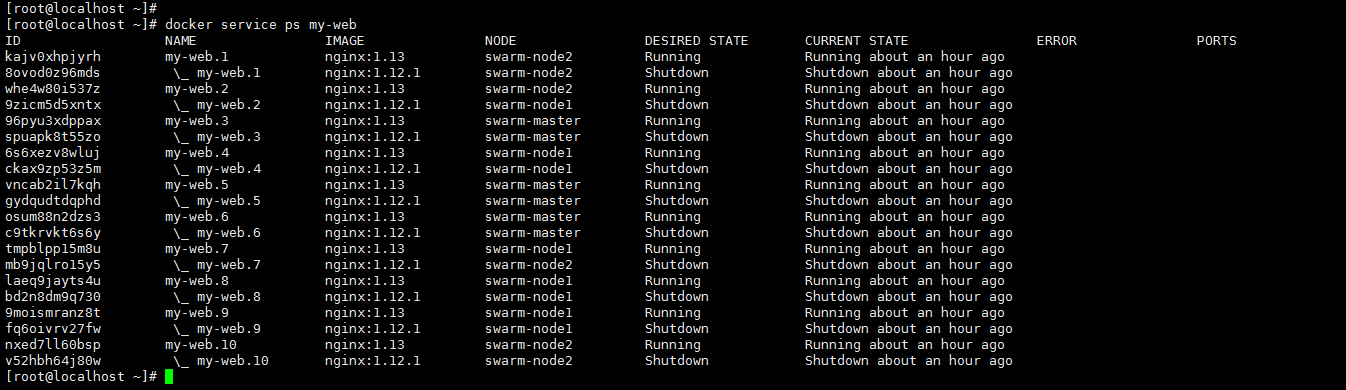
1 |
docker service ps my-web |

服务更新
|
1 |
docker service update --image nginx:1.13 my-web |
和上述设置的策略一致,两两更新
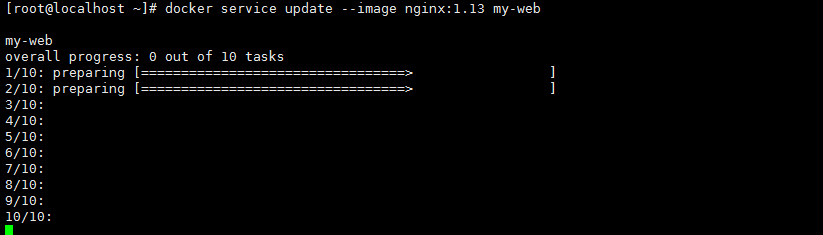
更新完成:
手动回滚(策略是失败会回滚,现在没有失败)
刚才nginx版本已经是1.13了,现在将其还原到1.12.1
|
1 |
docker service update --rollback my-web |

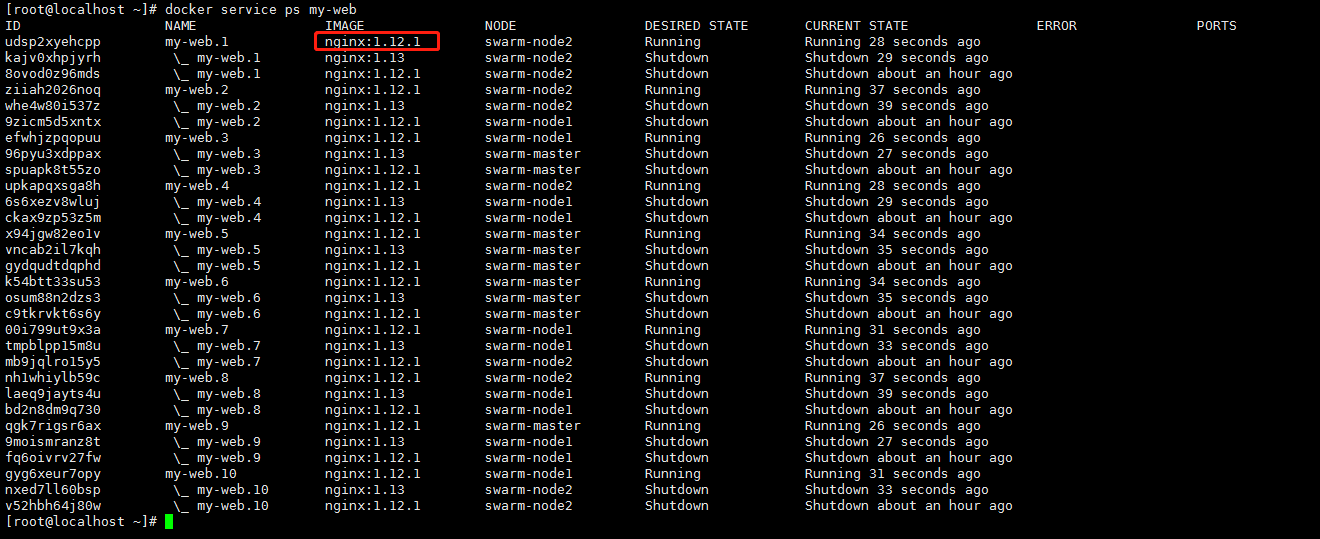
手动回滚完成
- 本文固定链接: https://www.yoyoask.com/?p=3076
- 转载请注明: shooter 于 SHOOTER 发表