ETCD参数说明

1、从快照对数据进行恢复
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
1.停止各个节点 systemctl stop etcd 2.备份 Etcd 数据目录 mv /apps/etcd /apps/etcd.bak 3.使用 Etcd 快照文件恢复 Etcd 数据 export ENDPOINTS=https://172.16.10.230:2379,https://172.16.10.231:2379,https://172.16.10.232:2379 etcdctl --cacert=/apps/etcd/ssl/etcd-ca.pem --cert=/apps/etcd/ssl/etcd-server.pem --key=/apps/etcd/ssl/etcd-server-key.pem --endpoints ${ENDPOINTS} snapshot restore /var/backups/kube_etcd/etcd-2024-0206-snapshot.db \ --name=etcd01 \ --initial-cluster=etcd01=https://172.16.10.230:2380 \ --initial-advertise-peer-urls=https://172.16.10.230:2380 \ --data-dir=/var/lib/etcd or etcdctl snapshot restore ./snapshot.db --name=dns02 \ --initial-advertise-peer-urls=https://172.16.10.230:2380 \ --initial-cluster-token=coredns \ --initial-cluster=k8s-master-1=https://172.16.10.230:2380,k8s-master-2=https://172.16.10.231:2380,k8s-master-3=https://172.16.10.232:2380 在恢复时快照完整性的检验是可选的。如果快照是通过 etcdctl snapshot save 得到的,它将有一个被 etcdctl snapshot restore 检查过的完整性hash。如果快照是从数据目录复制而来,没有完整性hash,因此它只能通过使用 --skip-hash-check 来恢复。 |
2、通过db文件进行恢复
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#通过默认db文件进行恢复 /apps/etcd/bin/etcdctl --cacert=/apps/etcd/ssl/etcd-ca.pem --cert=/apps/etcd/ssl/etcd-server.pem --key=/apps/etcd.bak/ssl/etcd-server-key.pem --endpoints ${ENDPOINTS} snapshot restore /apps/etcd/data/default.etcd.bak/member/snap/db \ --name=k8s-master-1 \ --initial-cluster=k8s-master-1=https://172.16.10.230:2380,k8s-master-2=https://172.16.10.231:2380,k8s-master-3=https://172.16.10.232:2380 \ --initial-advertise-peer-urls=https://172.16.10.232:2380 \ --data-dir=/apps/etcd/data/default.etcd \ --skip-hash-check #通过db文件进行恢复 /apps/etcd/bin/etcdctl snapshot restore ./db --name=k8s-master-1 \ --initial-advertise-peer-urls=https://172.16.10.230:2380 \ --initial-cluster-token=k8s-cluster \ --initial-cluster=k8s-master-1=https://172.16.10.230:2380,k8s-master-2=https://172.16.10.231:2380,k8s-master-2=https://172.16.10.232:2380 \ --data-dir=/apps/etcd/data/default.etcd \ --skip-hash-check |
|
1 |
systemctl start etcd |
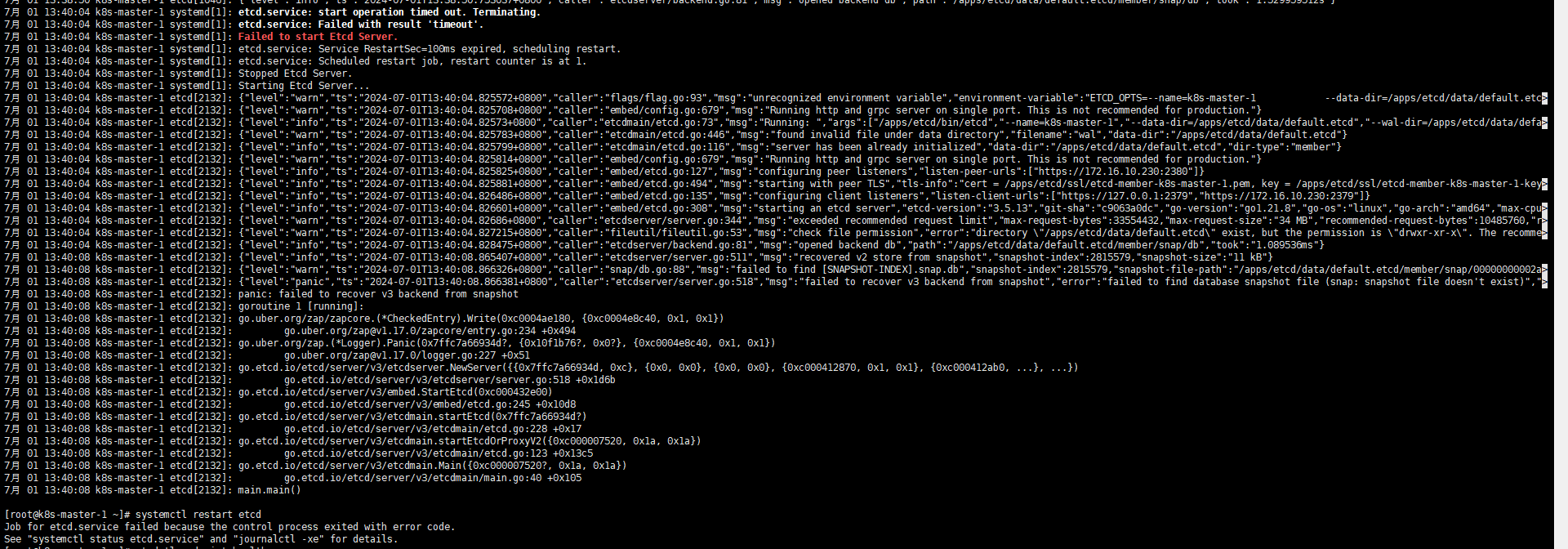
3、以上数据恢复失败,重新组织新的etcd集群,如下
直接删除数据重新拉起etcd集群(注意集群数据被清理)
|
1 2 3 4 |
删除etcd数据目录 rm -rf /apps/etcd/data/default.etcd/* 重新拉起etcd systemctl start etcd |
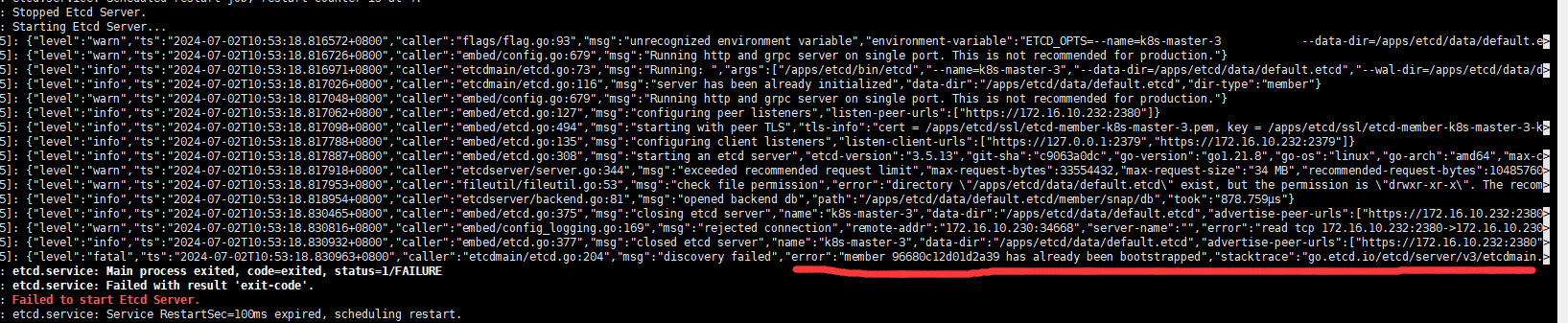
启动失败,id已存在
|
1 2 3 4 |
解决办法: 修改配置文件(new表示新节点,existing表示已存在) --initial-cluster-state=existing \ vim /apps/etcd/conf/etcd |
启动etcd
|
1 |
systemctl start etcd |

4、查看数据
|
1 2 3 4 5 6 7 8 9 10 11 |
export ETCDCTL_API=3 export ENDPOINTS=https://172.16.10.230:2379,https://172.16.10.231:2379,https://172.16.10.232:2379 alias etcdctl='/apps/etcd/bin/etcdctl --endpoints=${ENDPOINTS} --cacert=/apps/etcd/ssl/etcd-ca.pem --cert=/apps/etcd/ssl/etcd-server.pem --key=/apps/etcd/ssl/etcd-server-key.pem' ###查询etcd键值数据 etcdctl get / --prefix --keys-only ETCDCTL_API=3 /usr/local/bin/etcdctl endpoint health ETCDCTL_API=3 /usr/local/bin/etcdctl --write-out=table endpoint status |
|
1 2 3 |
参考文档: https://www.cnblogs.com/wangguishe/p/15548468.html https://www.zhaowenyu.com/etcd-doc/ops/data-backup-restore.html |
etcd集群删除与添加成员(适用集群更换或者添加新的节点)
更新一个节点
如果你想更新一个节点的 IP(peerURLS),首先你需要知道那个节点的 ID。你可以列出所有节点,找出对应节点的 ID
|
1 2 3 4 |
$ etcdctl member list 6e3bd23ae5f1eae0: name=node2 peerURLs=http://localhost:23802 clientURLs=http://127.0.0.1:23792 924e2e83e93f2560: name=node3 peerURLs=http://localhost:23803 clientURLs=http://127.0.0.1:23793 a8266ecf031671f3: name=node1 peerURLs=http://localhost:23801 clientURLs=http://127.0.0.1:23791 |
在本例中,我们假设要更新 ID 为 a8266ecf031671f3 的节点的 peerURLs 为:http://10.0.1.10:2380
|
1 2 |
$ etcdctl member update a8266ecf031671f3 http://10.0.1.10:2380 Updated member with ID a8266ecf031671f3 in cluster |
删除一个节点( 假设我们要删除 ID 为 a8266ecf031671f3 的节点 )
|
1 2 |
$ etcdctl member remove a8266ecf031671f3 Removed member a8266ecf031671f3 from cluster |
执行完后,目标节点会自动停止服务,并且打印一行日志:
|
1 |
this member has been permanently removed from the cluster. Exiting. |
如果删除的是 leader 节点,则需要耗费额外的时间重新选举 leader。
增加一个新的节点
增加一个新的节点分为两步:
- 通过 etcdctl 或对应的 API 注册新节点
- 使用恰当的参数启动新节点
第一步,假设我们要新加的节点取名为 k8s-master-2, peerURLs 是 http://172.16.10.231:2380
|
1 |
etcdctl member add k8s-master-2 --peer-urls=https://172.16.10.231:2380 |
etcdctl 在注册完新节点后,会返回一段提示,包含3个环境变量。然后在第二部启动新节点的时候,带上这3个环境变量即可。

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#在新节点启动etcd /apps/etcd/bin/etcd --name k8s-master-2 --initial-advertise-peer-urls https://172.16.10.231:2380 \ --data-dir /apps/etcd/data/default.etcd \ --listen-peer-urls https://172.16.10.231:2380 \ --listen-client-urls https://172.16.10.231:2379,http://127.0.0.1:2379 \ --advertise-client-urls https://172.16.10.231:2379 \ --initial-cluster-token k8s-cluster \ --initial-cluster k8s-master-1=https://172.16.10.230:2380,k8s-master-2=https://172.16.10.232:2380 \ --initial-cluster-state existing \ --trusted-ca-file=/apps/etcd/ssl/etcd-ca.pem \ --peer-trusted-ca-file=/apps/etcd/ssl/etcd-ca.pem \ --cert-file=/apps/etcd/ssl/etcd-server.pem \ --key-file=/apps/etcd/ssl/etcd-server-key.pem \ --peer-cert-file=/apps/etcd/ssl/etcd-member-k8s-master-2.pem \ --peer-key-file=/apps/etcd/ssl/etcd-member-k8s-master-2-key.pem >> etcd.log 2>&1 |
这样,新节点就会运行起来并且加入到已有的集群中了。

|
1 2 3 4 |
值得注意的是,如果原先的集群只有1个节点,在新节点成功启动之前,新集群并不能正确的形成。因为原先的单节点集群无法完成leader的选举。 直到新节点启动完,和原先的节点建立连接以后,新集群才能正确形成。 当第一个节点添加新节点后进入no leader状态得时候 ,第二个节点就可以启动了。第二个节点开始new hash得时候 其他节点就可以依次添加,并启动了。依次跑到new hash 基本就上来了 |
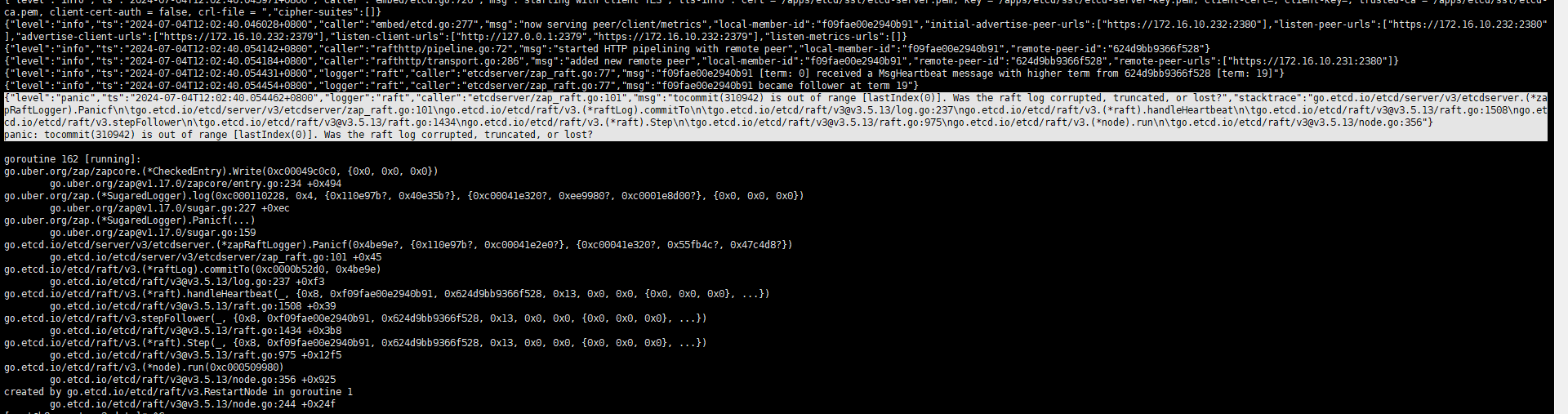
错误1【原节点损坏】
|
1 2 3 |
{"level":"panic","ts":"2024-07-04T12:02:40.054462+0800","logger":"raft","caller":"etcdserver/zap_raft.go:101","msg":"tocommit(310942) is out of range [lastIndex(0)]. Was the raft log corrupted, truncated, or lost?","stacktrace":"go.etcd.io/etcd/server/v3/etcdserver.(*zapRaftLogger).Panicf\n\tgo.etcd.io/etcd/server/v3/etcdserver/zap_raft.go:101\ngo.etcd.io/etcd/raft/v3.(*raftLog).commitTo\n\tgo.etcd.io/etcd/raft/v3@v3.5.13/log.go:237\ngo.etcd.io/etcd/raft/v3.(*raft).handleHeartbeat\n\tgo.etcd.io/etcd/raft/v3@v3.5.13/raft.go:1508\ngo.etcd.io/etcd/raft/v3.stepFollower\n\tgo.etcd.io/etcd/raft/v3@v3.5.13/raft.go:1434\ngo.etcd.io/etcd/raft/v3.(*raft).Step\n\tgo.etcd.io/etcd/raft/v3@v3.5.13/raft.go:975\ngo.etcd.io/etcd/raft/v3.(*node).run\n\tgo.etcd.io/etcd/raft/v3@v3.5.13/node.go:356"} panic: tocommit(310942) is out of range [lastIndex(0)]. Was the raft log corrupted, truncated, or lost? |
|
1 2 3 4 5 6 7 8 |
解决方案: 把之前执行member add的节点移除,重新添加一下应该就可以解决;我们这边生产环境就是这么解决的,如果有别的异常可以留言一起讨论 etcdctl member remove [id] etcdctl member add k8s-master-2 --peer-urls=https://172.x.x.x:2380 清理新加节点得数据 rm -rf /apps/etcd/data/default.etcd/* 然后启动 systemctl start etcd |
错误2 【集群成员被移除】
|
1 |
this member has been permanently removed from the cluster. Exiting. |
|
1 |
当前节点已被从集群中移除需要重新添加节点。 |
member add xxxx
错误3 【证书问题】
|
1 |
failed to get cluster response","address":"https://172.16.10.230:2380/members","error":"Get \"https://172.16.10.230:2380/members\": tls: failed to verify certificate: x509: certificate signed by unknown authority"} |
首先查看总证书和子证书中ip是否都正确
|
1 2 |
openssl x509 -in etcd-server.pem -text -noout openssl x509 -in etcd-member-k8s-master-1.pem -text -noout |
确认证书没问题后看下启动语句是否完全【https基本上证书该有的都要有】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
/apps/etcd/bin/etcd --name k8s-master-2 --initial-advertise-peer-urls https://172.16.10.231:2380 \ --data-dir /apps/etcd/data/default.etcd \ --listen-peer-urls https://172.16.10.231:2380 \ --listen-client-urls https://172.16.10.231:2379,http://127.0.0.1:2379 \ --advertise-client-urls https://172.16.10.231:2379 \ --initial-cluster-token k8s-cluster \ --initial-cluster k8s-master-1=https://172.16.10.230:2380,k8s-master-2=https://172.16.10.232:2380 \ --initial-cluster-state existing \ --trusted-ca-file=/apps/etcd/ssl/etcd-ca.pem \ --peer-trusted-ca-file=/apps/etcd/ssl/etcd-ca.pem \ --cert-file=/apps/etcd/ssl/etcd-server.pem \ --key-file=/apps/etcd/ssl/etcd-server-key.pem \ --peer-cert-file=/apps/etcd/ssl/etcd-member-k8s-master-2.pem \ --peer-key-file=/apps/etcd/ssl/etcd-member-k8s-master-2-key.pem >> etcd.log 2>&1 /apps/etcd/bin/etcd --name k8s-master-3 --initial-advertise-peer-urls https://172.16.10.232:2380 \ --data-dir /apps/etcd/data/default.etcd \ --listen-peer-urls https://172.16.10.232:2380 \ --listen-client-urls https://172.16.10.232:2379,http://127.0.0.1:2379 \ --advertise-client-urls https://172.16.10.232:2379 \ --initial-cluster-token k8s-cluster \ --initial-cluster k8s-master-2=https://172.16.10.231:2380,k8s-master-1=https://172.16.10.230:2380,k8s-master-3=https://172.16.10.232:2380 \ --initial-cluster-state existing \ --trusted-ca-file=/apps/etcd/ssl/etcd-ca.pem \ --peer-trusted-ca-file=/apps/etcd/ssl/etcd-ca.pem \ --cert-file=/apps/etcd/ssl/etcd-server.pem \ --key-file=/apps/etcd/ssl/etcd-server-key.pem \ --peer-cert-file=/apps/etcd/ssl/etcd-member-k8s-master-3.pem \ --peer-key-file=/apps/etcd/ssl/etcd-member-k8s-master-3-key.pem >> etcd.log 2>&1 |
|
1 2 |
Y哥笔记,恢复etcd https://system51.github.io/2019/09/11/etcd-Disaster-recovery/ |
- 本文固定链接: https://www.yoyoask.com/?p=11491
- 转载请注明: shooter 于 SHOOTER 发表
这个作者貌似有点懒,什么都没有留下。