Horizontal Pod Autoscaling(HPA)可以根据 CPU 利用率自动伸缩一个 Replication Controller、Deployment 或者 Replica Set 中的 Pod 数量
Horizontal Pod Autoscaling 可以根据 CPU 利用率自动伸缩一个 Replication Controller、Deployment 或者Replica Set 中的 Pod 数量
实测:
准备工作:
首先导入一下 hpa-example.tar镜像 这个是google专门为测试开发的一个example,利用它不断循环占用资源来测试 HAP
|
1 2 3 |
下载地址: https://pan.baidu.com/s/1JV-WlqYKnhg5T8UkDycTHQ 提取码:kxy0 |
下载完成后导入到各个节点
导入完成后给镜像打个标签
|
1 2 3 |
#给hpa-example镜像打个标签,因为默认他是latest 你懂的,启动的时候直接去对外请求了 docker tag 4ca4c13a6d7c gcr.io/google_containers/hpa-example:v1.0 |
1.启动一个php-apache的pod cpu资源请求限制为200兆
|
1 |
kubectl run php-apache --image=gcr.io/google_containers/hpa-example:v1.0 --requests=cpu=200m --expose --port=80 |
首先我们先查看下当前效果(使用如下命令如果报错,请耐心等一会,让资源加入进来)
|
1 2 3 4 5 6 7 8 |
[root@k8s-master kube-prometheus]# kubectl top pod NAME CPU(cores) MEMORY(bytes) load-generator-7d549cd44-mjz2z 0m 0Mi php-apache-64987dd9c4-jcg6j 0m 11Mi [root@k8s-master kube-prometheus]# kubectl top pod php-apache-64987dd9c4-jcg6j NAME CPU(cores) MEMORY(bytes) php-apache-64987dd9c4-jcg6j 0m 11Mi [root@k8s-master kube-prometheus]# |
然后我们进行HPA控制器的创建
|
1 |
kubectl autoscale deployment php-apache --cpu-percent=40 --min=1 --max=10 |
|
1 2 |
[root@k8s-master HPA]# kubectl autoscale deployment php-apache --cpu-percent=40 --min=1 --max=10 horizontalpodautoscaler.autoscaling/php-apache autoscaled |
查看当前hpa
|
1 |
kubectl get hpa |
|
1 2 3 |
[root@k8s-master HPA]# kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE php-apache Deployment/php-apache 0%/40% 1 10 1 31s |
好,需要设置的已经设置完了。下来进行压力测试
1.首先先开启一个busybox的pod
|
1 |
kubectl run -i --tty load-generator --image=busybox /bin/sh |
2.然后我们在这个pod里面 get 我们那个php-apache的页面让他无限的去访问
|
1 |
while true; do wget -q -O- http://php-apache.default.svc.cluster.local; done |

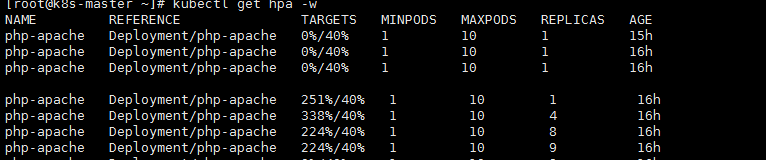
3.我们可以开个新的窗口来看他的资源
|
1 |
kubectl get hpa |
|
1 |
kubectl get pod |
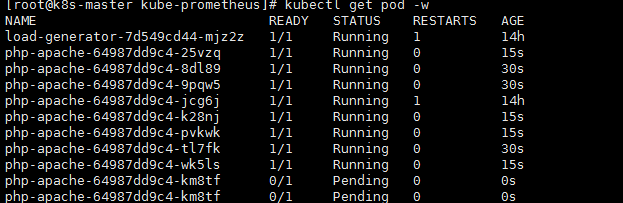

由此可见:可以看到只要php-apachepod的负载大于40% 就会创建一个新的pod副本来分担其压力
2.减小负载(关掉busybox pod),查看是否回收
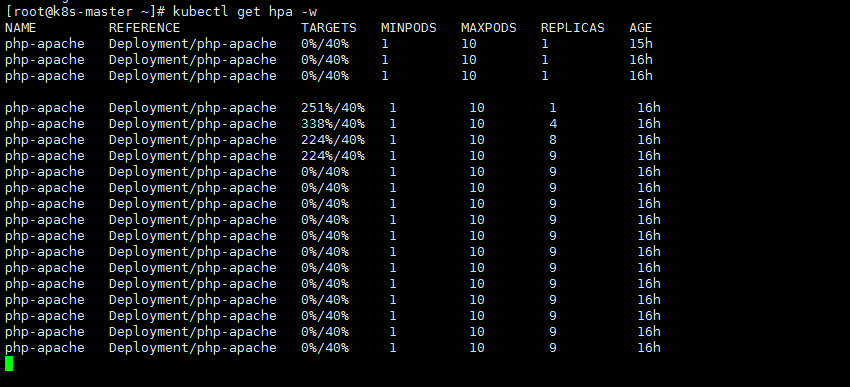
等待pod回收,等啊等,睡觉了…
早上起来
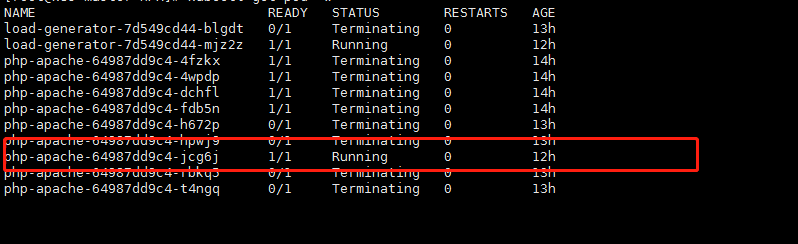
可以看到已经回收至1个pod
为什么回收这么慢呢?回收特别慢是很合理的。它怕突然又来大压力把pod给挤死
目前的hpa的稳定版,仅支持cpu和内存去进行所谓的扩容缩。那么以后肯定会有以网络啊 磁盘io 来加入到扩容缩当中来。
资源限制 – Pod
Kubernetes 对资源的限制实际上是通过 cgroup 来控制的,cgroup 是容器的一组用来控制内核如何运行进程的 相关属性集合。针对内存、CPU 和各种设备都有对应的 cgroup
默认情况下,Pod 运行没有 CPU 和内存的限额。 这意味着系统中的任何 Pod 将能够像执行该 Pod 所在的节点一 样,消耗足够多的 CPU 和内存 。一般会针对某些应用的 pod 资源进行资源限制,这个资源限制是通过 resources 的 requests 和 limits 来实现
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
#在yaml文件里,资源限制写在resources下,限制cpu和内存使用 spec: containers: - image: xxxx imagePullPolicy: Always name: auth ports: - containerPort: 8080 protocol: TCP resources: limits: #2.硬限制(如果你需要更多资源,我最大给你4个cpu去用,最大给你2G内存去用,再大就不可以了) cpu: "4" memory: 2Gi requests: #1.软限制(意思是他刚开始运行的时候cpu是250hz,他分配的内存是250M) cpu: 250m memory: 250Mi #requests 要分配的资源(参考创建php-apache那句),limits 为最高请求的资源值。可以简单理解为初始值和最大值 |
资源限制 – 名称空间 (基于命名空间(配置更广泛 针对整个命名空间))
1.计算资源配额
|
1 2 3 4 5 6 7 8 9 10 11 12 |
apiVersion: v1 kind: ResourceQuota metadata: name: compute-resources namespace: spark-cluster spec: hard: pods: "20" #最大允许创建20个pod requests.cpu: "20" #cpu资源默认分配20 requests.memory: 100Gi #整个命名空间下能够使用的最大内存 综合起来100G limits.cpu: "40" # 如果你有压力我最大给40 limits.memory: 200Gi # 如果你有压力最多给内存200G |
2.配置对象数量配额限制
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
apiVersion: v1 kind: ResourceQuota metadata: name: object-counts namespace: spark-cluster spec: hard: configmaps: "10" #最大10个 persistentvolumeclaims: "4" #pvc最多4个 replicationcontrollers: "20" #rc 最多20个 secrets: "10" #secrets最多10个 services: "10" #svc 最多10个 services.loadbalancers: "2" #云服务器负载最多2个 |
3.我怎么设置一个pod里能够使用资源的默认值呢?
配置默认值,避免oom (配置 CPU 和 内存 LimitRang)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
apiVersion: v1 kind: LimitRange metadata: name: mem-limit-range spec: limits: - default: #最大分配 memory: 50Gi cpu: 5 defaultRequest: #默认分配 memory: 1Gi cpu: 1 type: Container |
默认分配一个pod 1G内存 1个cpu 如果你觉得不够用 最大分配给你 5个cpu 50G内存
- 本文固定链接: https://www.yoyoask.com/?p=2482
- 转载请注明: shooter 于 SHOOTER 发表