
kubernetes coredns容器状态一直为CrashLoopBackOff,状态不断重启,在running和CrashLoopBackOff直接不停转换
查看日志
|
1 |
kubectl logs -f coredns-5c98db65d4-p7wvx -n kube-system |
错误内容如下:
|
1 2 3 4 |
log is DEPRECATED and will be removed in a future version. Use logs instead. E0304 01:56:44.618841 1 reflector.go:134] github.com/coredns/coredns/plugin/kubernetes/controller.go:315: Failed to list *v1.Service: Get https://10.96.0.1:443/api/v1/services?limit=500&resourceVersion=0: dial tcp 10.96.0.1:443: connect: no route to host E0304 01:56:44.618841 1 reflector.go:134] github.com/coredns/coredns/plugin/kubernetes/controller.go:315: Failed to list *v1.Service: Get https://10.96.0.1:443/api/v1/services?limit=500&resourceVersion=0: dial tcp 10.96.0.1:443: connect: no route to host log: exiting because of error: log: cannot create log: open /tmp/coredns.coredns-5c98db65d4-g7pmz.unknownuser.log.ERROR.20200304-015644.1: no such file or directory |
查看详细
|
1 |
kubectl describe pod coredns-5c98db65d4-p7wvx -n kube-system |
|
1 |
Readiness probe failed: Get http://172.17.67.3:8181/ready: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers) |
从日志上看是到10.96.0.1的443网络不可达导致
阶段2
|
1 |
kubectl get pod -n kube-system -o wide |
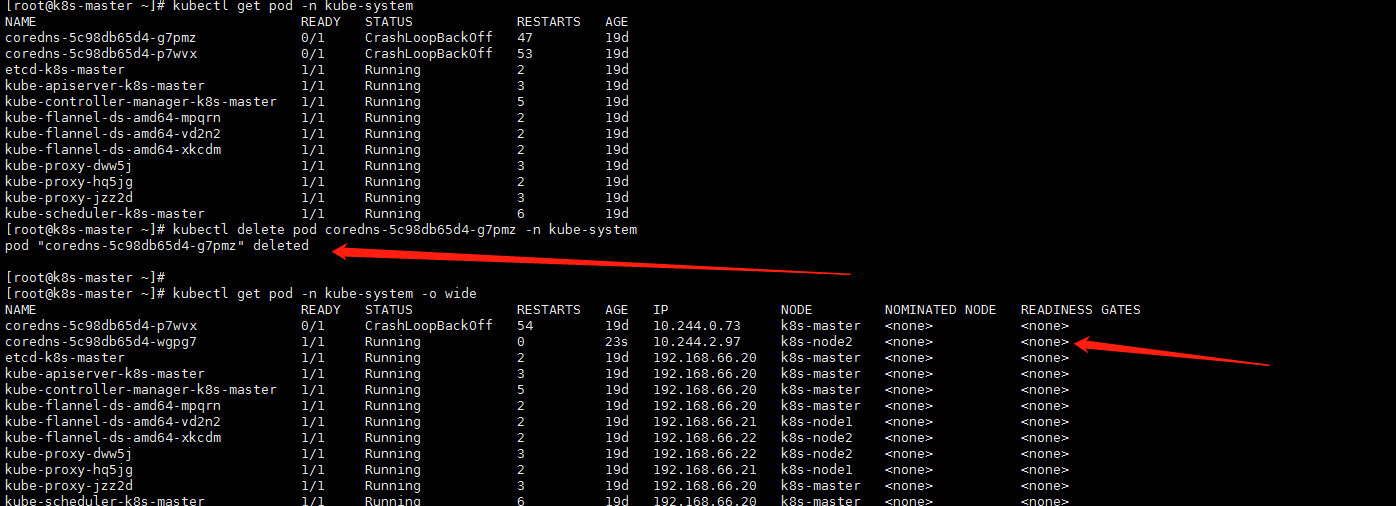
通过以上命令发现两个coreDns的2个pod节点都分配在master节点上,node节点没有分配上去,有了一个想法,删除一个coredns的pod,重新分配试试
|
1 |
kubectl delete pod coredns-9d85f5447-ct5c8 -n kube-system |
|
1 |
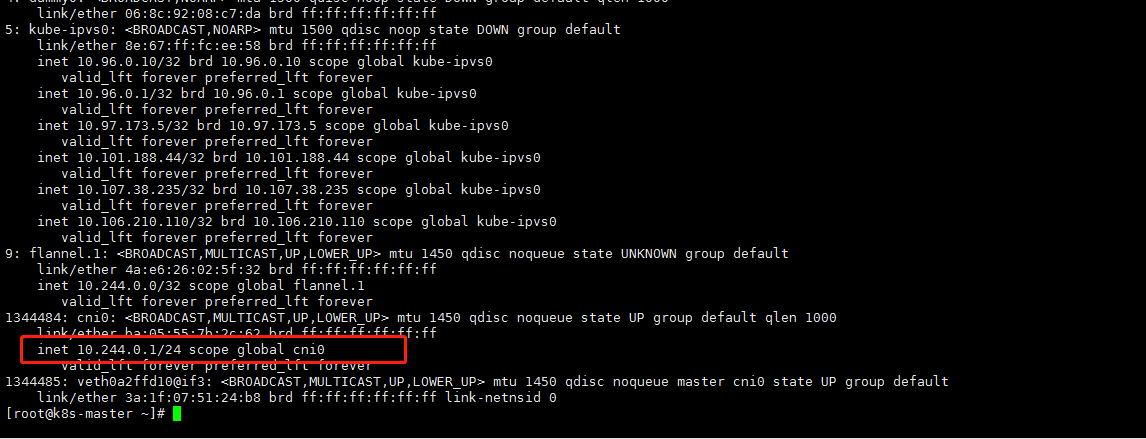
删除其中一个节点,如图,集群马上重新创建了一个coreDns节点,新的pod分配到了node 115上,等了一会,发现node节点上的pod状态竟然正常了,发现一个疑点,node节点上的pod ip为10.244.2.1,master节点的pod ip为172.17.67.3,记得当初k8s集群初始化使用的默认参数为--pod-network-cidr=10.244.0.0/16,原因应该为master节点地址分配有问题。 |
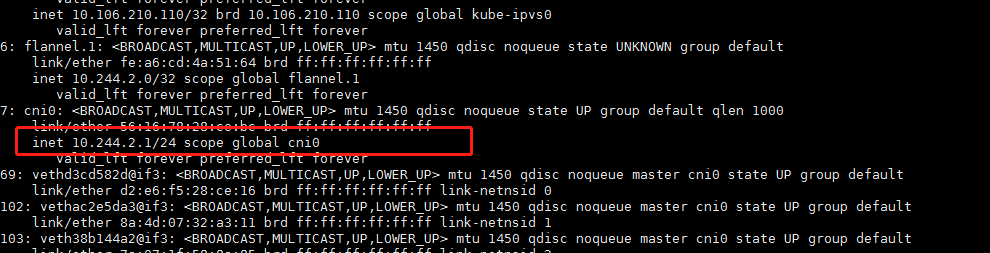
通过以上的分析,我们分别在master节点上执行ip add查看flannel网卡地址分配情况。发现master节点cni0地址为172.17.67.1,而node2节点地址为10.244.2.1,不在初始化分配地址段10.244.0.0/16内,我们找到原因了,将master节点pod地址重新分配即可。
阶段3
上网搜资料上看,有网友建议kubeadm reset重置来解决,但是此方法比较麻烦,我采用如下方法
|
1 |
ip link set cni0 down;brctl delbr cni0 |
先停止cni0 网卡,然后使用brctl 命令删除此网卡,删除后flannel会立刻重新创建此网卡,使用ip add查看,网卡地址已经变成10.244段。
注意:
- brctl 命令可以使用命令yum install -y bridge-utils安装
- 停止网卡可删除操作最好使用分号一起执行,否者停止后启动很快,会提示此网卡为up状态,不可删除。
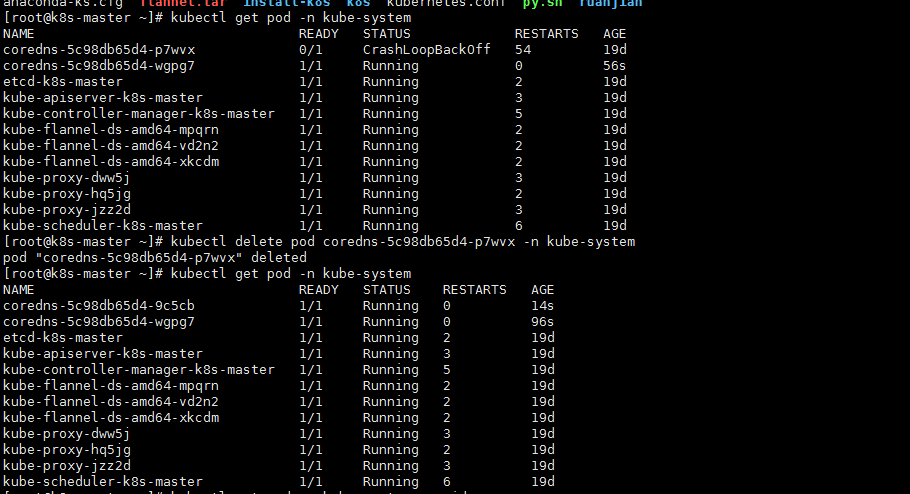
然后使用命令删掉coreDns 状态为CrashLoopBackOff 容器,让他自动新建,新建后的容器状态就正常了
|
1 |
kubectl get pod -n kube-system |
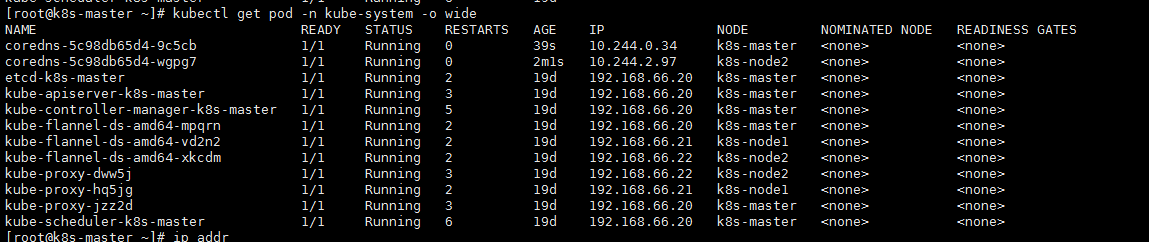
再看下master的cni0网卡地址是否变成了10.244.*.*
- 本文固定链接: https://www.yoyoask.com/?p=2209
- 转载请注明: shooter 于 SHOOTER 发表
这个作者貌似有点懒,什么都没有留下。