deamonSet
保证集群中每个节点上都运行一个Pod副本,当有新的节点加入集群时,DaemonSet会为他们新增一个Pod,当有节点从移除时候,节点上的Pod也会被垃圾收集器回收。删除DaemonSet会删除它创建的所有Pod。
DaemonSet就像计算机的守护进程,他能够运行集群存储,日志收集,和监控等,这些服务一般都是集群的必备基础服务
创建一个daemonSet
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
apiVersion: apps/v1 kind: DaemonSet metadata: name: deamonset-example labels: app: daemonset spec: selector: matchLabels: name: deamonset-example template: metadata: labels: name: deamonset-example spec: containers: - name: daemonset-example image: hub.atshooter.com/k8s/nginx:v1.0 |
matchLabels.name 与 metadata.name 一定要对应 切记切记。否则创建不成功的

你会发现创建了2个deamonset-example 节点1和节点2 分别一个。为什么是2个?为什么主节点master没有创建?
记住,所有pod都不会运行到主节点上来,这个跟污点有关系,默认情况下我们的主节点并不会加入到我们的调度任务中来。
所以只有节点1和节点2会创建deamonSet-example副本
job
Job 负责批处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个 Pod 成功结束
- spec.template格式同Pod
- RestartPolicy仅支持Never或OnFailure
- 单个Pod时,默认Pod成功运行后Job即结束
- .spec.completions 标志Job结束需要成功运行的Pod个数,默认为1
- .spec.parallelism 标志并行运行的Pod的个数,默认为1
- .spec.activeDeadlineSeconds 标志失败Pod的重试最大时间,超过这个时间不会继续重试
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
apiVersion: batch/v1 kind: Job metadata: name: pi spec: template: metadata: name: pi spec: containers: - name: pi image: perl command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"] restartPolicy: Never |
restartPolicy
- Never永不重启
- OnFailure 失败后重启
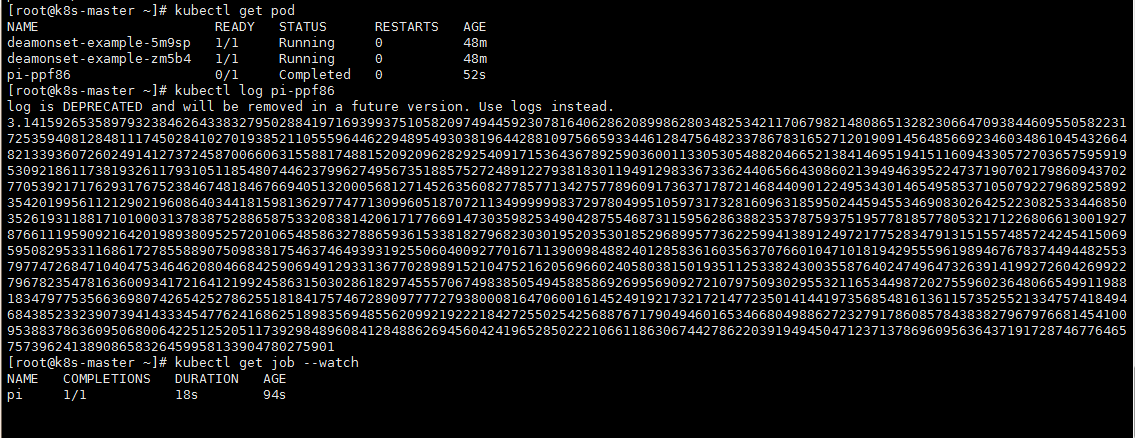
job 一次性任务,当pod运行后执行完就停止了
CronJob
|
1 2 3 |
CronJob 通过创建Job来对pod进行管理,每一个 Job 对象都会持有一个或者多个 Pod,而每一个 CronJob 就会持有多个 Job 对象,CronJob 能够按照时间对任务进行调度,它与 crontab 非常相似,我们可以使用 Cron 格式快速指定任务的调度时间: cronjob运行流程为 cronjob会先创建job ——> 然后job会创建pod ——> 然后执行调度 ——> 然后销毁pod 理解为 在高频率的定时任务就是不断的创建pod然后删除pod 个人觉得这样很占用资源 |
CronJob Spec
- spec.template格式同Pod
- RestartPolicy仅支持Never或OnFailure
- 单个Pod时,默认Pod成功运行后Job即结束
- .spec.completions 标志Job结束需要成功运行的Pod个数,默认为1
- .spec.parallelism 标志并行运行的Pod的个数,默认为1
- spec.activeDeadlineSeconds 标志失败Pod的重试最大时间,超过这个时间不会继续重试
- .spec.schedule :调度,必需字段,指定任务运行周期,格式同 Cron
- .spec.jobTemplate :Job 模板,必需字段,指定需要运行的任务,格式同 Job
- .spec.startingDeadlineSeconds :启动 Job 的期限(秒级别),该字段是可选的。如果因为任何原因而错 过了被调度的时间,那么错过执行时间的 Job 将被认为是失败的。如果没有指定,则没有期限
- .spec.concurrencyPolicy并发策略,该字段也是可选的。它指定了如何处理被 Cron Job 创建的 Job 的并发执行。只允许指定下面策略中的一种:
- Allow (默认):允许并发运行 Job
- Forbid :禁止并发运行,如果前一个还没有完成,则直接跳过下一个
- Replace :取消当前正在运行的 Job,用一个新的来替换
- 注意,当前策略只能应用于同一个 Cron Job 创建的 Job。如果存在多个 Cron Job,它们创建的 Job 之间总是允许并发运行。
- .spec.suspend :挂起,该字段也是可选的。如果设置为 true ,后续所有执行都会被挂起。它对已经开始执行的 Job 不起作用。默认值为 false 。
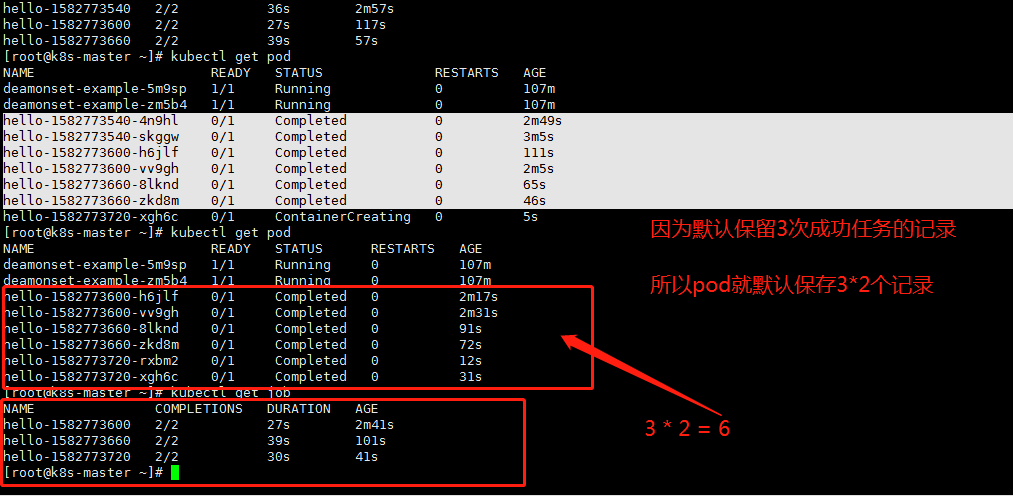
- .spec.successfulJobsHistoryLimit 和 .spec.failedJobsHistoryLimit :历史限制,是可选的字段。它们指定了可以保留多少完成和失败的 Job。默认情况下,它们分别设置为 3 和 1 。设置限制的值为 0 ,相关类型的 Job 完成后将不会被保留。
Cron Job 管理基于时间的 Job,即:
- 在给定时间点只运行一次
- 周期性地在给定时间点运行
典型的用法如下所示:
- 在给定的时间点调度 Job 运行
- 创建周期性运行的 Job,例如:数据库备份、发送邮件
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
apiVersion: batch/v1beta1 kind: CronJob metadata: name: hello spec: schedule: "*/1 * * * *" jobTemplate: spec: completions: 1 #Job结束需要成功运行的Pod个数,默认为1 parallelism: 1 #标志并行运行的Pod的个数,默认为1 template: spec: containers: - name: hello image: busybox args: - /bin/sh - -c - date; echo Hello from the Kubernetes cluster restartPolicy: OnFailure #失败就重新执行 |
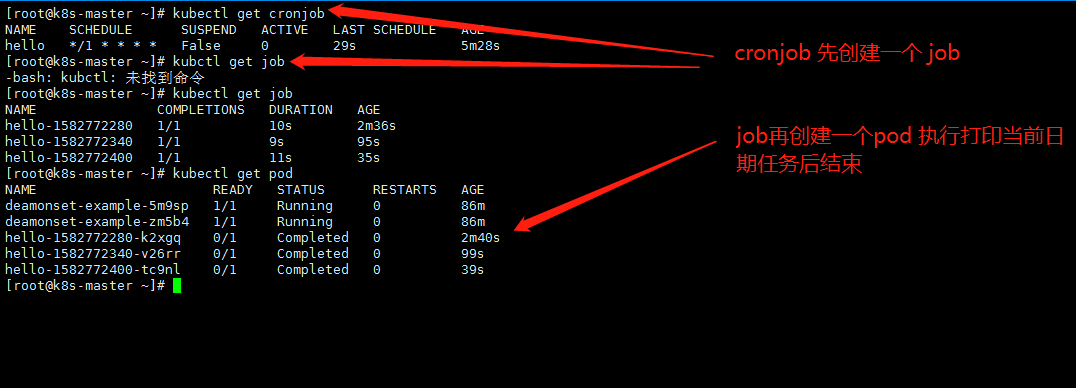
cronjob 每分钟创建一个job ,job创建一个pod,执行完任务后终止。
一共显示执行了3次就停止了,是为什么呢?
CronJob 中保存的任务其实是有上限的,spec.successfulJobsHistoryLimit 和 spec.failedJobsHistoryLimit 分别记录了能够保存的成功或者失败的任务上限,超过这个上限的任务都会被删除,默认情况下这两个属性分别为 spec.successfulJobsHistoryLimit=3 和 spec.failedJobsHistoryLimit=1。
如果
completions: 2
那么

这就意味着 cronjob 创建的job,每次要创建2个pod,然后等待2个pod执行完任务后终止。当然如果是周期性的,那就是周期性任务每次都要创建一个2个pod的job
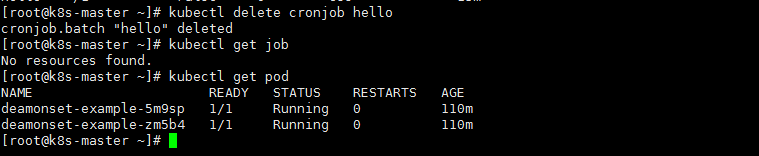
删除cronjob
|
1 2 3 4 |
kubectl delete cronjob [cronJobName] #有些低版本删除cronjob 后还需要 删除job |
- 本文固定链接: https://www.yoyoask.com/?p=2144
- 转载请注明: shooter 于 SHOOTER 发表