组件说明
- 1.MetricServer:是kubernetes集群资源使用情况的聚合器,收集数据给kubernetes集群内使用,如kubectl,hpa,scheduler等。
- 2.PrometheusOperator:是一个系统监测和警报工具箱,用来存储监控数据。
- 3.NodeExporter:用于各node的关键度量指标状态数据。
- 4.KubeStateMetrics:收集kubernetes集群内资源对象数据,制定告警规则。
- 5.Prometheus:采用pull方式收集apiserver,scheduler,controller-manager,kubelet组件数据,通过http协议传输。
- 6.Grafana:是可视化数据统计和监控平台。
开始安装
1.准备工作
|
1 2 3 |
#首先创建2个文件夹 mkdir -p /install-k8s/plugins/prometeus cd /install-k8s/plugins/prometeus |
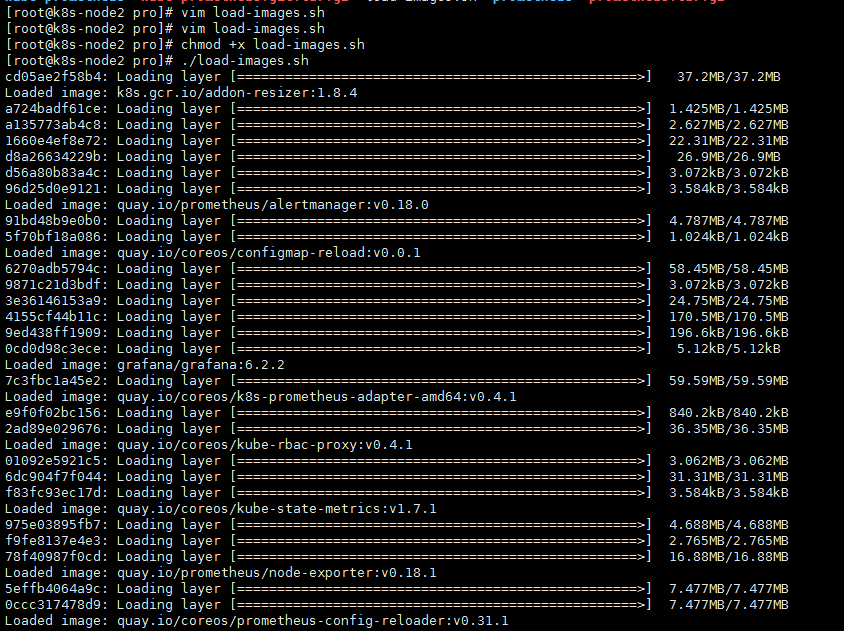
导入镜像(这个镜像包太大,而且需要科学上网,建议先导入)
|
1 2 |
所需镜像和构建包下载地址:https://pan.baidu.com/s/1Yf1tXnF2bFtwTvyzxm444A 提取码:mig4 |
下载好后解压,然后运行目录那个批量导入镜像脚本
2.开始构建
可以用我提供的包,也可以去git下载
|
1 |
git clone https://github.com/coreos/kube-prometheus.git |
解压构建包,进入到manifests目录下
|
1 2 |
tar -zxf kube-prometheus.git.tar.gz cd kube-prometheus/manifests |
因为prometheus默认的访问方式是cluserIP,对我们来说不是很友好,所以我们将以下几个文件做下修改
1.修改 grafana-service.yaml 文件,使用 nodepode 方式访问 grafana
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
apiVersion: v1 kind: Service metadata: labels: app: grafana name: grafana namespace: monitoring spec: type: NodePort #添加内容 ports: - name: http port: 3000 targetPort: http nodePort: 30100 #添加内容 selector: app: grafana |
2.修改 prometheus-service.yaml,改为 nodepode
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
apiVersion: v1 kind: Service metadata: labels: prometheus: k8s name: prometheus-k8s namespace: monitoring spec: type: NodePort #修改内容 ports: - name: web port: 9090 targetPort: web nodePort: 30200 #修改内容 selector: app: prometheus prometheus: k8s sessionAffinity: ClientIP |
3.修改 alertmanager-service.yaml,改为 nodepode
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
apiVersion: v1 kind: Service metadata: labels: alertmanager: main name: alertmanager-main namespace: monitoring spec: type: NodePort #修改内容 ports: - name: web port: 9093 targetPort: web nodePort: 30300 #修改内容 selector: alertmanager: main app: alertmanager sessionAffinity: ClientIP |
然后开始构建
|
1 2 |
#这里多运行几次,直到不报错,因为他们要互相建立连接 kubectl apply -f ../manifests/ |
构建完成后查看
|
1 2 |
#查看是否正常运行 需要注意的是 preference 所有插件安装在 monitoring 命名空间下 |
然后等他运行几分钟然后查看 kubectl top node
|
1 2 3 4 5 |
[root@k8s-master kube-prometheus]# kubectl top node NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% k8s-master 796m 19% 1220Mi 31% k8s-node1 187m 4% 901Mi 47% k8s-node2 229m 5% 1300Mi 69% |
指标含义:
- 和k8s中的request、limit一致,CPU单位100m=0.1 内存单位1Mi=1024Ki
- pod的内存值是其实际使用量,也是做limit限制时判断oom的依据。pod的使用量等于其所有业务容器的总和,不包括 pause 容器,值等于cadvisr中的container_memory_working_set_bytes指标
- node的值并不等于该node 上所有 pod 值的总和,也不等于直接在机器上运行 top 或 free 看到的值
然后我们查看他当前运行的状态
|
1 |
kubectl get svc --all-namespace |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
[root@k8s-master kube-prometheus]# kubectl get svc --all-namespaces NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE default kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 28h kube-system heapster ClusterIP 10.98.3.29 <none> 8082/TCP 4h48m kube-system kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 33d kube-system kubelet ClusterIP None <none> 10250/TCP 6m24s kube-system kubernetes-dashboard NodePort 10.97.52.234 <none> 443:31557/TCP 7h kube-system tiller-deploy ClusterIP 10.109.179.15 <none> 44134/TCP 30h monitoring alertmanager-main NodePort 10.105.134.84 <none> 9093:30300/TCP 7m5s monitoring alertmanager-operated ClusterIP None <none> 9093/TCP,6783/TCP 6m12s monitoring grafana NodePort 10.96.77.114 <none> 3000:30100/TCP 7m1s monitoring kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 7m1s monitoring node-exporter ClusterIP None <none> 9100/TCP 6m59s monitoring prometheus-adapter ClusterIP 10.109.154.81 <none> 443/TCP 6m49s monitoring prometheus-k8s NodePort 10.100.81.202 <none> 9090:30200/TCP 6m46s monitoring prometheus-operated ClusterIP None <none> 9090/TCP 6m9s monitoring prometheus-operator ClusterIP None <none> 8080/TCP 7m6s |
访问 prometheus
|
1 2 3 |
#宿主机 浏览器访问 http://192.168.66.20:30200 #这个就是我们的prometheus收集端 |

进入status>target 可以看到 prometheus 已经成功连接上了 k8s 的 apiserver

查看 service-discovery
|
1 |
http://192.168.66.20:30200/service-discovery |

prometheus 的 WEB 界面上提供了基本的查询 K8S 集群中每个 POD 的 CPU 使用情况,查询条件如下:
|
1 |
sum by (pod_name)( rate(container_cpu_usage_seconds_total{image!="", pod_name!=""}[1m] ) ) |
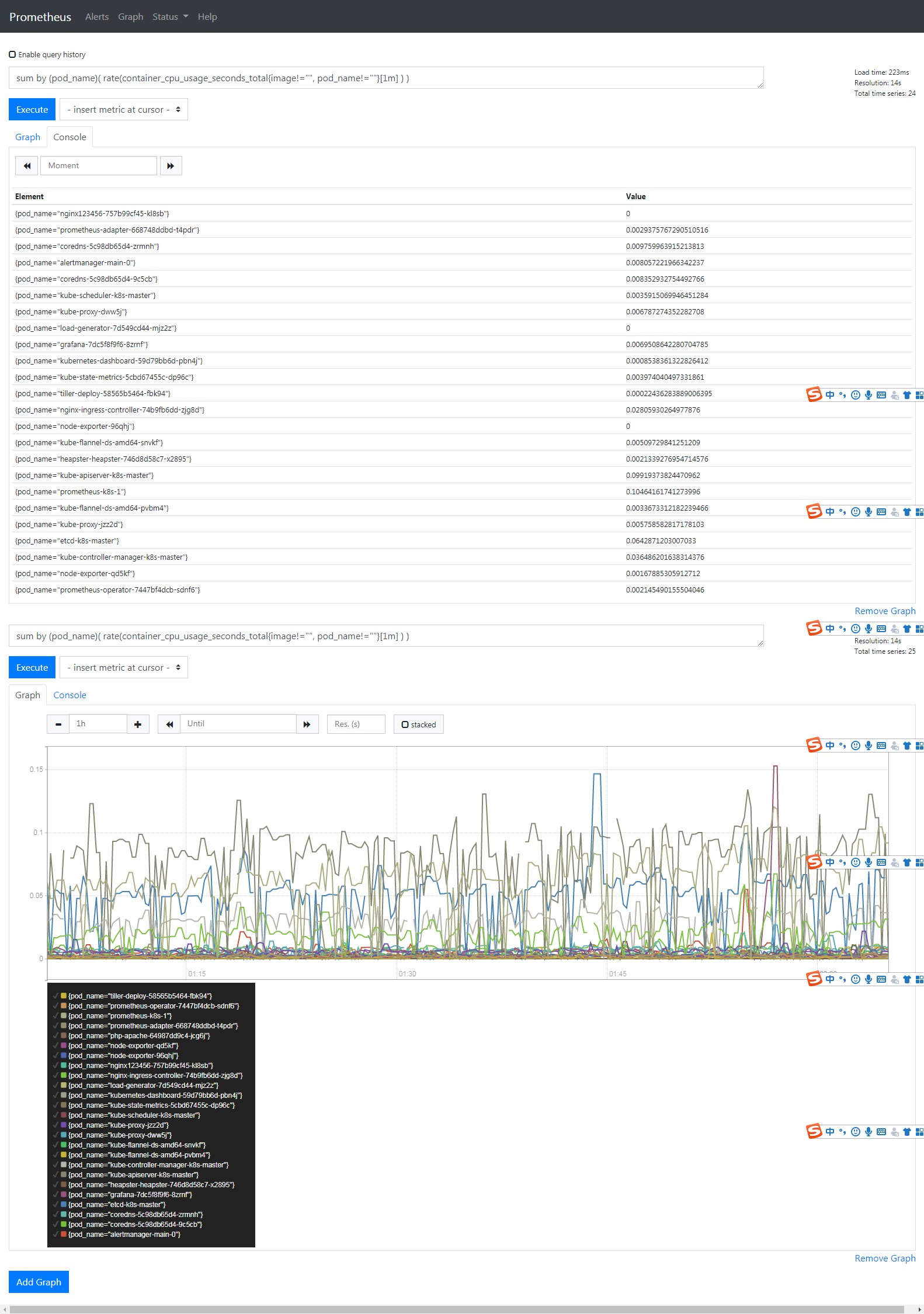
上述的查询有出现数据,说明 node-exporter 往 prometheus 中写入数据正常,接下来我们就可以访问 grafana 组件,实现更友好的 webui 展示数据了
访问 grafana
查看grafana暴露端口号
|
1 |
kubectl get service -n monitoring | grep grafana |

如上可以看到 grafana 的端口号是 30100,
浏览器访问 http://MasterIP:30100
用户名密码默认 admin/admin

第一次登录会让你修改密码,修改下就好了
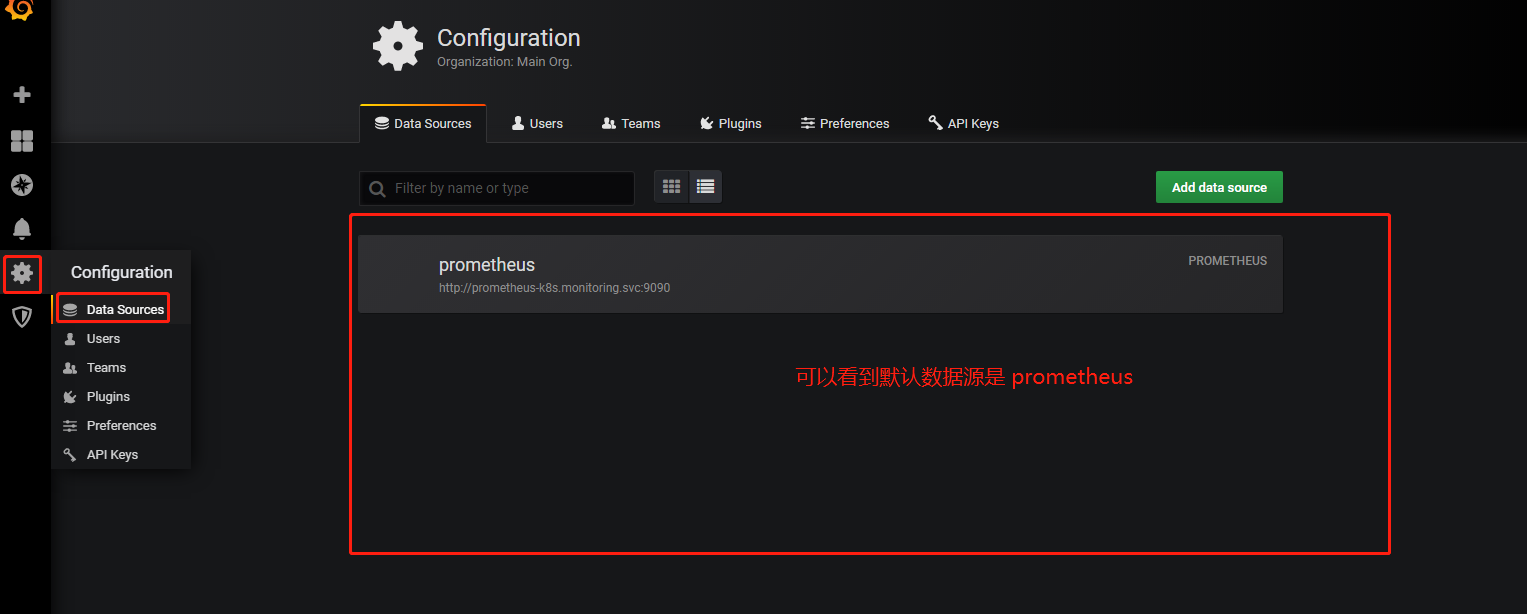
登录后添加数据源
|
1 |
grafana 默认已经添加了 Prometheus 数据源,grafana 支持多种时序数据源,每种数据源都有各自的查询编辑器 |
目前官方支持了如下几种数据源:

点击我们的数据源Prometheus进入
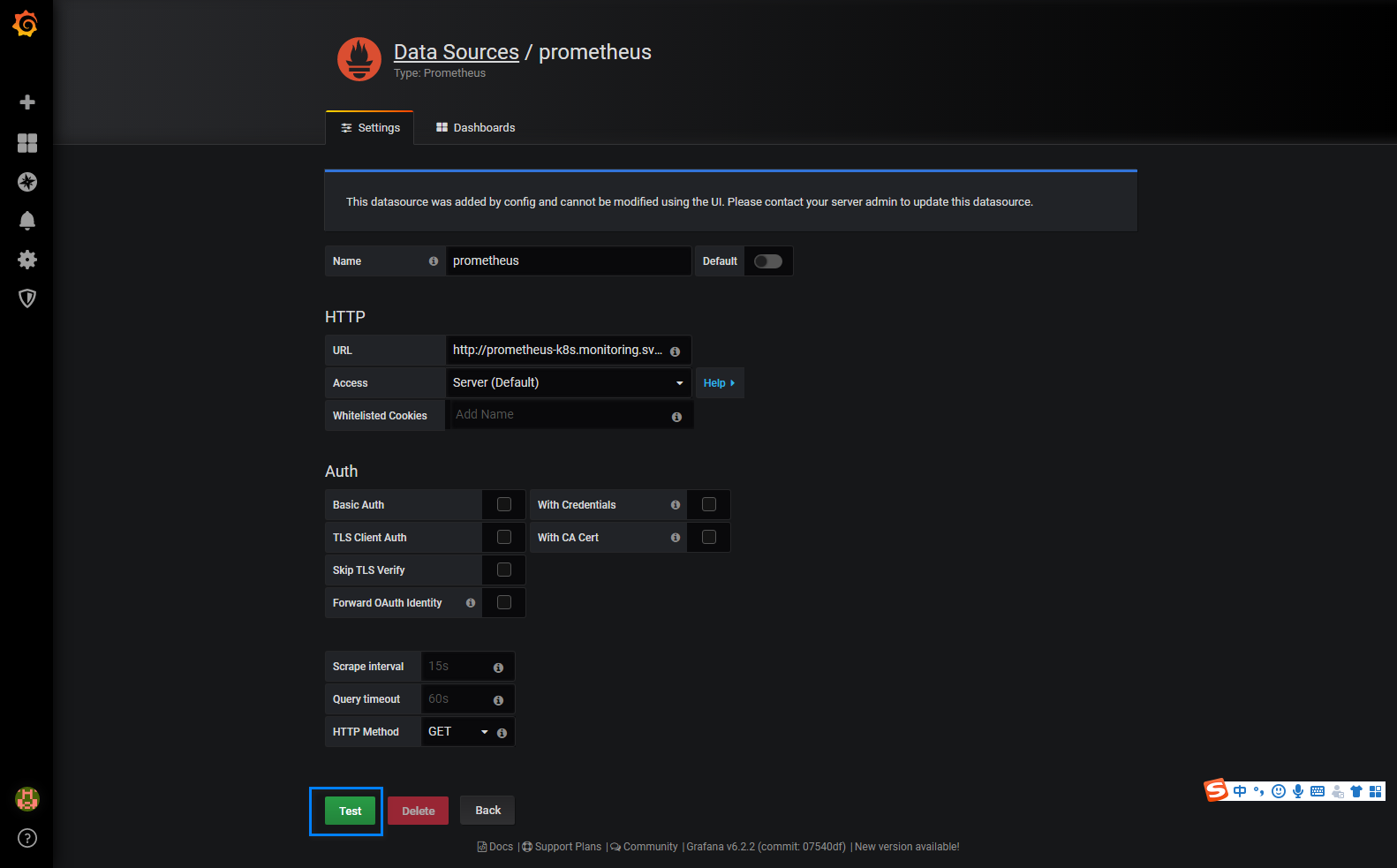
然后点击Test 没问题,然后在dashbords里导入一些节点
然后点击home
选择你要查看的资源监控
选择pod或者节点监控 查看图标

接下来配置alertmanager+dingtalk告警
alertmanager.yml
- 配置alertmanager配置文件, 从上面的的文件包中,找出alertmanager相关的yaml文件,移动到alertmanager中。然后配置alertmanager-secret
|
1 2 |
cd kube-prometheus/manifests mv alertmanager-* alertmanager/ && cd alertmanager/ |
|
1 |
cat alertmanager-secret.yaml |

将你的配置文件base64加密后,替换他这个原有的。(当然你也可以使用configmap的方式挂载进去)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
global: resolve_timeout: 5m route: group_by: ['alertname'] group_wait: 10s group_interval: 10s repeat_interval: 5m receiver: 'web.hook' receivers: - name: 'web.hook' webhook_configs: - send_resolved: true url: 'http://webhook-dingtalk:8060/dingtalk/webhook/send' inhibit_rules: - source_match: severity: 'critical' target_match: severity: 'warning' equal: ['alertname', 'dev', 'instance'] |
然后删除之前的alertmanager容器,重新应用。
dingding
|
1 |
git clone https://github.com/timonwong/prometheus-webhook-dingtalk.git |
这个需要从git拉取代码,然后编译,然后打包成镜像才可以使用。编译方式请戳这里
编译好后打包,打包要注意修改Dockerfile这个文件,可能作者写错了
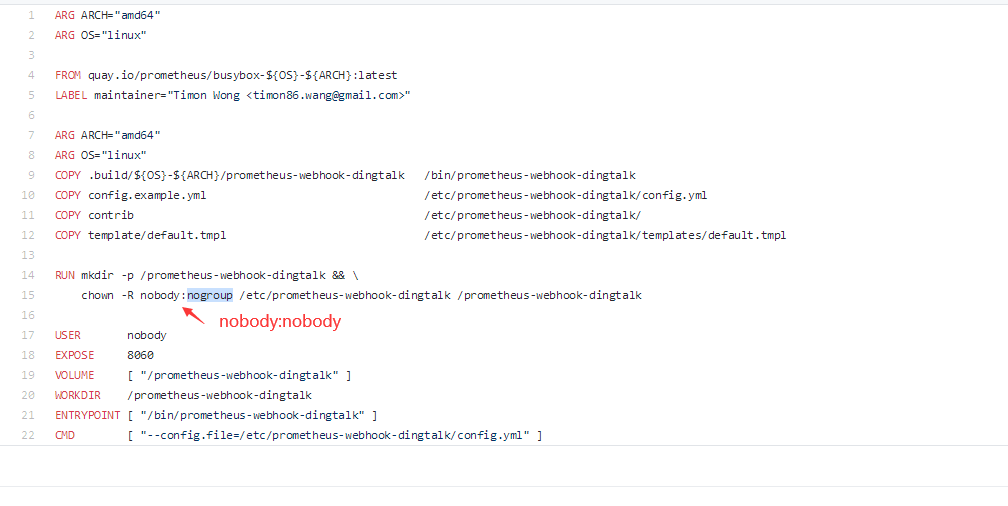
Dockerfile[修改后的]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
ARG ARCH="amd64" ARG OS="linux" FROM quay.io/prometheus/busybox-${OS}-${ARCH}:latest LABEL maintainer="Timon Wong <timon86.wang@gmail.com>" ARG ARCH="amd64" ARG OS="linux" COPY .build/${OS}-${ARCH}/prometheus-webhook-dingtalk /bin/prometheus-webhook-dingtalk COPY config.example.yml /etc/prometheus-webhook-dingtalk/config.yml COPY contrib /etc/prometheus-webhook-dingtalk/ COPY template/default.tmpl /etc/prometheus-webhook-dingtalk/templates/default.tmpl RUN mkdir -p /prometheus-webhook-dingtalk && \ chown -R nobody:nobody /etc/prometheus-webhook-dingtalk /prometheus-webhook-dingtalk USER nobody EXPOSE 8060 VOLUME [ "/prometheus-webhook-dingtalk" ] WORKDIR /prometheus-webhook-dingtalk ENTRYPOINT [ "/bin/prometheus-webhook-dingtalk" ] CMD [ "--config.file=/etc/prometheus-webhook-dingtalk/config.yml" ] |
然后编译打包成镜像。这里有我本人镜像,需要的自行下载
|
1 2 |
链接:https://pan.baidu.com/s/1CE1l_pClr3uozsLSqv2BTw 提取码:6vff |
配置
|
1 2 |
#配置文件 dingtalk-configmap |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
apiVersion: v1 kind: ConfigMap metadata: name: dingtalk-config namespace: monitoring labels: app: dingtalk-config data: config.yml: | templates: - /etc/prometheus-webhook-dingtalk/templates/default.tmpl targets: webhook: url: https://oapi.dingtalk.com/robot/send?access_token=0df42dc863ec08274b3f3226ca13 secret: SECcef7ffa8990cdd29b9d0cbe5c08b121cf7db message: title: '{{ template "ding.link.title" . }}' text: '{{ template "ding.link.content" . }}' |
|
1 2 |
#消息模板 dingtalk-template |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 |
apiVersion: v1 kind: ConfigMap metadata: name: dingtalk-template namespace: monitoring labels: app: dingtalk-template data: default.tmpl: | {{ define "__subject" }}[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}] {{ .GroupLabels.SortedPairs.Values | join " " }} {{ if gt (len .CommonLabels) (len .GroupLabels) }}({{ with .CommonLabels.Remove .GroupLabels.Names }}{{ .Values | join " " }}{{ end }}){{ end }}{{ end }} {{ define "__alertmanagerURL" }}{{ .ExternalURL }}/#/alerts?receiver={{ .Receiver }}{{ end }} {{ define "__text_alert_list" }}{{ range . }} **Labels** {{ range .Labels.SortedPairs }}> - {{ .Name }}: {{ .Value | markdown | html }} {{ end }} **Annotations** {{ range .Annotations.SortedPairs }}> - {{ .Name }}: {{ .Value | markdown | html }} {{ end }} **Source:** [{{ .GeneratorURL }}]({{ .GeneratorURL }}) {{ end }}{{ end }} {{ define "default.__text_alert_list" }}{{ range . }} --- **告警级别:** {{ .Labels.severity | upper }} **运营团队:** {{ .Labels.team | upper }} **触发时间:** {{ dateInZone "2006.01.02 15:04:05" (.StartsAt) "Asia/Shanghai" }} **事件信息:** {{ range .Annotations.SortedPairs }}> - {{ .Name }}: {{ .Value | markdown | html }} {{ end }} **事件标签:** {{ range .Labels.SortedPairs }}{{ if and (ne (.Name) "severity") (ne (.Name) "summary") (ne (.Name) "team") }}> - {{ .Name }}: {{ .Value | markdown | html }} {{ end }}{{ end }} {{ end }} {{ end }} {{ define "default.__text_alertresovle_list" }}{{ range . }} --- **告警级别:** {{ .Labels.severity | upper }} **运营团队:** {{ .Labels.team | upper }} **触发时间:** {{ dateInZone "2006.01.02 15:04:05" (.StartsAt) "Asia/Shanghai" }} **结束时间:** {{ dateInZone "2006.01.02 15:04:05" (.EndsAt) "Asia/Shanghai" }} **事件信息:** {{ range .Annotations.SortedPairs }}> - {{ .Name }}: {{ .Value | markdown | html }} {{ end }} **事件标签:** {{ range .Labels.SortedPairs }}{{ if and (ne (.Name) "severity") (ne (.Name) "summary") (ne (.Name) "team") }}> - {{ .Name }}: {{ .Value | markdown | html }} {{ end }}{{ end }} {{ end }} {{ end }} {{/* Default */}} {{ define "default.title" }}{{ template "__subject" . }}{{ end }} {{ define "default.content" }}#### \[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}\] **[{{ index .GroupLabels "alertname" }}]({{ template "__alertmanagerURL" . }})** {{ if gt (len .Alerts.Firing) 0 -}}  **====侦测到故障====** {{ template "default.__text_alert_list" .Alerts.Firing }} {{- end }} {{ if gt (len .Alerts.Resolved) 0 -}} {{ template "default.__text_alertresovle_list" .Alerts.Resolved }} {{- end }} {{- end }} {{/* Legacy */}} {{ define "legacy.title" }}{{ template "__subject" . }}{{ end }} {{ define "legacy.content" }}#### \[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}\] **[{{ index .GroupLabels "alertname" }}]({{ template "__alertmanagerURL" . }})** {{ template "__text_alert_list" .Alerts.Firing }} {{- end }} {{/* Following names for compatibility */}} {{ define "ding.link.title" }}{{ template "default.title" . }}{{ end }} {{ define "ding.link.content" }}{{ template "default.content" . }}{{ end }} |
消息模板2 Qist
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
{{ define "wechat.default.message" }} {{- if gt (len .Alerts.Firing) 0 -}} {{- range $index, $alert := .Alerts -}} {{- if eq $index 0 -}} **********告警通知********** 告警类型: {{ $alert.Labels.alertname }} 告警级别: {{ $alert.Labels.severity }} {{- end }} ===================== 告警主题: {{ $alert.Annotations.summary }} 告警详情: {{ $alert.Annotations.description }} 故障时间: {{ $alert.StartsAt.Local }} {{ if gt (len $alert.Labels.instance) 0 -}}故障实例: {{ $alert.Labels.instance }}{{- end -}} {{- end }} {{- end }} {{- if gt (len .Alerts.Resolved) 0 -}} {{- range $index, $alert := .Alerts -}} {{- if eq $index 0 -}} **********恢复通知********** 告警类型: {{ $alert.Labels.alertname }} 告警级别: {{ $alert.Labels.severity }} {{- end }} ===================== 告警主题: {{ $alert.Annotations.summary }} 告警详情: {{ $alert.Annotations.description }} 故障时间: {{ $alert.StartsAt.Local }} 恢复时间: {{ $alert.EndsAt.Local }} {{ if gt (len $alert.Labels.instance) 0 -}}故障实例: {{ $alert.Labels.instance }}{{- end -}} {{- end }} {{- end }} {{- end }} |
|
1 |
webhook-dingtalk.yaml |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
apiVersion: apps/v1beta2 kind: Deployment metadata: labels: app: webhook-dingtalk name: webhook-dingtalk namespace: monitoring #需要和alertmanager在同一个namespace spec: replicas: 1 selector: matchLabels: app: webhook-dingtalk template: metadata: labels: app: webhook-dingtalk spec: containers: - image: registry.cn-hangzhou.aliyuncs.com/shooer/by_docker_shooter:prometheus_dingtalk_v0.1 name: webhook-dingtalk args: - "--config.file=/etc/prometheus-webhook-dingtalk/config.yml" volumeMounts: - name: webdingtalk-configmap mountPath: /etc/prometheus-webhook-dingtalk/ - name: webdingtalk-template mountPath: /etc/prometheus-webhook-dingtalk/templates/ ports: - containerPort: 8060 protocol: TCP imagePullSecrets: - name: IfNotPresent volumes: - name: webdingtalk-configmap configMap: name: dingtalk-config - name: webdingtalk-template configMap: name: dingtalk-template --- apiVersion: v1 kind: Service metadata: labels: app: webhook-dingtalk name: webhook-dingtalk namespace: monitoring #需要和alertmanager在同一个namespace spec: ports: - name: http port: 8060 protocol: TCP targetPort: 8060 selector: app: webhook-dingtalk type: ClusterIP |

|
1 |
- 本文固定链接: https://www.yoyoask.com/?p=2462
- 转载请注明: shooter 于 SHOOTER 发表