1.k8s 架构体系了解吗?简单描述下
|
1 |
这道题主要考察 k8s 体系,涉及的范围其实太广泛,可以从本身 k8s 组件、存储、网络、监控等方面阐述,当时我主要将 k8s 的每个组件功能都大概说了一下。 |
Master节点主要有四个组件
- api-server
- controller-manager
- kube-scheduler
- etcd
- cloud-controller-manager
api-server
|
1 |
kube-apiserver 作为 k8s 集群的核心,负责整个集群功能模块的交互和通信,集群内的各个功能模块如 kubelet、controller、scheduler 等都通过 api-server 提供的接口将信息存入到 etcd 中,当需要这些信息时,又通过 api-server 提供的 restful 接口,如get、watch 接口来获取,从而实现整个 k8s 集群功能模块的数据交互。 |
controller-manager
|
1 2 3 4 |
controller-manager 作为 k8s 集群的管理控制中心,负责集群内 Node、Namespace、Service、Token、Replication 等资源对象的管理,使集群内的资源对象维持在预期的工作状态。 每一个 controller 通过 api-server 提供的 restful 接口实时监控集群内每个资源对象的状态,当发生故障,导致资源对象的工作状态发生变化,就进行干预,尝试将资源对象从当前状态恢复为预期的工作状态. 常见的 controller 有 Namespace Controller、Node Controller、Service Controller、ServiceAccount Controller、Token Controller、ResourceQuote Controller、Replication Controller等。 |
kube-scheduler
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
kube-scheduler 简单理解为通过特定的调度算法和策略为待调度的 Pod 列表中的每个 Pod 选择一个最合适的节点进行调度,调度主要分为两个阶段,预选阶段和优选阶段,其中预选阶段是遍历所有的 node 节点,根据策略和限制筛选出候选节点,优选阶段是在第一步的基础上,通过相应的策略为每一个候选节点进行打分,分数最高者胜出,随后目标节点的 kubelet 进程通过 api-server 提供的接口监控到 kube-scheduler 产生的 pod 绑定事件,从 etcd 中获取 Pod 的清单,然后下载镜像,启动容器。 预选阶段的策略有: (1) MatchNodeSelector:判断节点的 label 是否满足 Pod 的 nodeSelector 属性值。 (2) PodFitResource:判断节点的资源是否满足 Pod 的需求,批判的标准是:当前节点已运行的所有 Pod 的 request值 + 待调度的 Pod 的 request 值是否超过节点的资源容量。 (3) PodFitHostName:判断节点的主机名称是否满足 Pod 的 nodeName 属性值。 (4) PodFitHostPort:判断 Pod 的端口所映射的节点端口是否被节点其他 Pod 所占用。 (5) CheckNodeMemoryPressure:判断 Pod 是否可以调度到内存有压力的节点,这取决于 Pod 的 Qos 配置,如果是 BestEffort(尽量满足,优先级最低),则不允许调度。 (6) CheckNodeDiskPressure:如果当前节点磁盘有压力,则不允许调度。 优选阶段的策略有: (1) SelectorSpreadPriority:尽量减少节点上同属一个 SVC/RC/RS 的 Pod 副本数,为了更好的实现容灾,对于同属一个 SVC/RC/RS 的 Pod 实例,应尽量调度到不同的 node 节点。 (2) LeastRequestPriority:优先调度到请求资源较少的节点,节点的优先级由节点的空闲资源与节点总容量的比值决定的,即(节点总容量 - 已经运行的 Pod 所需资源)/ 节点总容量,CPU 和 Memory 具有相同的权重,最终的值由这两部分组成。 (3) BalancedResourceAllocation:该策略不能单独使用,必须和 LeaseRequestPriority 策略一起结合使用,尽量调度到 CPU 和 Memory 使用均衡的节点上。 |
ETCD
|
1 |
键值对数据库,存储k8s集群的所有重要信息(持久化),k8s集群中的所有资源对象都存储在etcd中 |
Node节点主要有三个组件
- kubelet
- kube-proxy
- docker
kubelet
|
1 |
在 k8s 集群中,每个 node 节点都会运行一个 kubelet 进程,该进程用来处理 Master 节点下达到该节点的任务,同时,通过 api-server 提供的接口定期向 Master 节点报告自身的资源使用情况,并通过 cadvisor 组件监控节点和容器的使用情况。 |
kube-proxy
|
1 |
kube-proxy 就是一个智能的软件负载均衡器,将 service 的请求转发到后端具体的 Pod 实例上,并提供负载均衡和会话保持机制,目前有三种工作模式,分别是:用户模式(userspace)、iptables 模式和 IPVS 模式。 |
2.Kubernetes与Docker Swarm的区别如何?
|
1 2 3 4 5 |
Kubernetes 是基于 google 自身多年使用 linux 容器的经验创建出来的,所以可以说它是 Google自身多年操作经验的一个复制,只是 google 把这些操作经验应用到了 Docker 上。使用Kubernetes 来管理容器在多个方面都将带来很大的好处,而其中最重要的就是 Google 把他们多年使用容器的经验带入了这个工具。Kubernetes 解决了许多 Docker 自身的问题。通过 Kubernetes,你可以在容器中使用实际的物理存储单元,从而我们可以很方便的把容器移动到其他机器上,而不丢失任何数据; Kubernetes 使用 flannel 来创建容器之间的网络;Kubernetes 集成了 load balancer;Kubernetes 使用 etcd 来实现服务发现,诸如此类的东西还有很多。从一定意义上来说,Kubernetes 提升了 Docker 容器集群的管理层次,但同时它的学习难度也是非常大的。 Docker Swarm 就截然不同, 它就是针对 Docker 容器技术创建的集群工具。最关键的是 Dcoker Swarm 对外提供的是完全标准的 Docker API,因此任何使用 Docker API 与 Docker 进行通讯的工具(Docker ClI, Docker Compose, Dokku, Krane)都可以完全无缝地和 Docker Swarm协同工作。这一点对 Docker Swarm 来说既是一个优点,也是一个缺点。优点就是你可以使用熟悉的工具集,缺点也显而易见,就是你只能做 Docker API 规定的事情。如果 Docker API 不支持某个你要的功能,你就不能直接使用 Docker Swarm 来实现,你可能需要使用一些特别的技巧来实现。 另外,个人感觉,swarm属官方出品,过于依赖于docker本身功能,很多重要功能还要依赖于阿里云技术团队的二次开发,未来不可控. |
3.什么是Kubernetes?
|
1 |
Kubernetes 是一个开源的、用于管理云平台中多个主机上的容器化应用。它的目标是让部署容器化应用变得简单且高效。同时,它提供了应用部署、规划、更新、维护的机制。 |
3.1 容器编排的价值和好处是什么?
|
1 |
容器编排的好处有很多,这里仅以微服务架构为例。微服务是解决企业 IT 长期演进的一种方案,适用于迭代发展很快的系统。同时,它是一种考虑小型团队人员扩展以处理大问题的方法。 |
3.2 容器和主机部署应用的区别是什么?
|
1 |
速度、效率和可靠性方面的价值 |
3.3 Kubernetes 有哪些组件?
|
1 2 3 4 5 6 7 8 9 10 11 |
master控制平面组件 kube-apiserver etcd kube-scheduler kube-controller-manager cloud-controller-manager Node 组件 kubelet kube-proxy 容器运行时 插件(Addons)DNS Web 界面(仪表盘) 容器资源监控 集群层面日志 |
3.4 如何在 Kubernetes 中实现负载均衡?
|
1 2 3 |
1.nodeport+外部的LB 2.用ingress做lb |
3.5 在构建和管理生产集群时遇到的主要问题是什么?
|
1 |
3.6 为什么你会建议公司在云中构建自己的 K8S 集群而不是使用托管服务?
|
1 |
3.7 什么是 Istio 和 Linkerd?
|
1 |
3.8 什么是 Kubernetes Operator?
|
1 |
3.9 Replica Set 和 Replication Controller之间有什么区别?
|
1 |
Replica Set 和 Replication Controller几乎完全相同。它们都确保在任何给定时间运行指定数量的pod副本。不同之处在于复制pod使用的选择器。Replica Set使用基于集合的选择器,而Replication Controller使用基于权限的选择器。 |
3.10 docker 后端存储驱动 devicemapper、overlay 几种的区别?
|
1 |
3.11 k8s 中服务级别,怎样设置服务的级别才是最高的
|
1 |
3.12 kubelet 监控 Node 节点资源使用是通过什么组件来实现的?
|
1 |
3.13 docker runc 漏洞是怎么修复的?
|
1 |
来自群题库:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
一、 Kubernetes基础组件有哪些,什么功能? 二、 一个Pod创建流程 三、 网络选型需要注意什么? 四、 Etcd用的什么算法,简单解释下 五、 Pod中pending状态,是什么原因产生的?pod出现问题,排查思路 六、 请回答Kubernetes发布策略(4种) 七、 手写raft 八、 你们监控用的什么?怎么利用普罗米修斯监控pod信息、Kubernetes的状态?如果你来设计相关的监控如何落地? 九、 如果利用Kubernetes实现滚动更新,怎么配置文件机制? 十、 StatefulSet是怎么实现滚动更新的? 十一、 就基本的k8s架构问题,遇到问题怎么处理? 十二、 Kubectl exec实现的原理是什么? 十三、 如何实现schedule水平扩展? 十四、 为什么k8s要用申明式? 十五、 了解过endpointslice么?怎么实现的? 十六、 容器的驱逐时间是多少?由什么决定的? 十七、 节点的NotReady是什么导致的?NotReady会导致什么问题? 十八、 Api-Server到etcd怎么保证事件不丢失? 十九、 SideCar要保证顺序启动的话如何保证?几种方式可以做到? 二十、 有了解过QoS么?怎么实现的? 二十一、 详细叙述Kube-Proxy的原理 二十二、 K8s的Pause容器有什么用?是否可用去掉? 二十三、 K8s的Serivce和EndPoint是如何管理和互相影响的? 二十四、 StatefulSets和Operator的区别是什么? |
4.Kubernetes与Docker有什么关系?
|
1 2 3 |
Docker是一个开源的应用容器引擎,开发者可以打包他们的应用及依赖到一个可移植的容器中,发布到Linux机器上,也可实现虚拟化。 k8s是一个开源的容器集群管理工具系统,可以实现容器集群的自动化部署、自动扩缩容、维护等功能。 说白了,我们用kubernetes去管理Docker集群,即可以将Docker看成Kubernetes内部使用的低级别组件。另外,kubernetes不仅仅支持Docker,还支持Rocket,这是另一种容器技术。 |
什么是pod
|
1 2 |
简而言之,pod就是一组容器,我们在使用docker的那个阶段,每个项目由有个服务,由不同容器组合运行。而pod就是对这一组密切相关的容器的一个逻辑总称。即一组业务容器跑在一个k8s的pod中。 每个pod中会有一个pause容器,这个容器与其他的业务容器都没有关系,以这个pause容器的状态来代表这个pod的状态,pause容器有一个ip地址,和一个存储卷,pod中的其他容器共享pause容器的ip地址和存储,这样就做到了文件共享和互信。 |
5.什么是Container Orchestration?(容器编排)
|
1 2 3 |
应用一般由单独容器化的组件(通常称为微服务)组成,且必须按顺序在网络级别进行组织,以使其能够按照计划运行。以这种方法对多个容器进行组织的流程即称为容器编排。 考虑一个应用程序有5-6个微服务的场景。现在,这些微服务被放在单独的容器中,但如果没有容器编排就无法进行通信。因此,所有的容器编排意味着各个容器中的所有服务协同工作,以满足单个服务器的需求。 |
6.你对Kube-proxy有什么了解?
|
1 |
kube-proxy 就是一个智能的软件负载均衡器,将 service 的请求转发到后端具体的 Pod 实例上,并提供负载均衡和会话保持机制,目前有三种工作模式,分别是:用户模式(userspace)、iptables 模式和 IPVS 模式。 |
7.Kubernetes有什么特点?
|
1 2 3 |
可移植: 支持公有云,私有云,混合云,多重云 可扩展: 模块化, 插件化, 可挂载, 可组合 自动化: 自动部署,自动重启,自动复制,自动伸缩/扩展 |
8.什么是Google容器引擎?
|
1 |
Google Container Engine(GKE)是Docker容器和集群的开源管理平台。这个基于Kubernetes的引擎仅支持在Google的公共云服务中运行的群集。 |
9.什么是Kubectl?
|
1 |
Kubectl是一个平台,您可以使用该平台将命令传递给集群。因此,它基本上为CLI提供了针对Kubernetes集群运行命令的方法,以及创建和管理Kubernetes组件的各种方法。 |
10.什么是Kubelet?
|
1 |
这是一个代理服务,它在每个节点上运行,并使从服务器与主服务器通信。因此,Kubelet处理PodSpec中提供给它的容器的描述,并确保PodSpec中描述的容器运行正常。 |
11.kube-apiserver和kube-scheduler的作用是什么?
|
1 2 3 |
kube-apiserver 作为 k8s 集群的核心,负责整个集群功能模块的交互和通信,集群内的各个功能模块如 kubelet、controller、scheduler 等都通过 api-server 提供的接口将信息存入到 etcd 中,当需要这些信息时,又通过 api-server 提供的 restful 接口,如get、watch 接口来获取,从而实现整个 k8s 集群功能模块的数据交互。 kube-scheduler 是 kubernetes 的调度器,通过特定的调度算法和策略为待调度的 Pod 列表中的每个 Pod 选择一个最合适的节点进行调度。 |
12.你能简要介绍一下Kubernetes控制管理器(controller-manager)吗?
|
1 2 3 4 |
controller-manager 作为 k8s 集群的管理控制中心,负责集群内 Node、Namespace、Service、Token、Replication 等资源对象的管理,使集群内的资源对象维持在预期的工作状态。 每一个 controller 通过 api-server 提供的 restful 接口实时监控集群内每个资源对象的状态,当发生故障,导致资源对象的工作状态发生变化,就进行干预,尝试将资源对象从当前状态恢复为预期的工作状态. 常见的 controller 有 Namespace Controller、Node Controller、Service Controller、ServiceAccount Controller、Token Controller、ResourceQuote Controller、Replication Controller等。 |
13.什么是ETCD?
|
1 |
键值对数据库,存储k8s集群的所有重要信息(持久化),k8s集群中的所有资源对象都存储在etcd中 |
14.Kubernetes有哪些不同类型的服务?
|
1 2 3 4 |
Cluster IP Node Port Load Balancer External Name |
15.你对Kubernetes的负载均衡器(kube-proxy)有什么了解?
|
1 |
kube-proxy 就是一个智能的软件负载均衡器,将 service 的请求转发到后端具体的 Pod 实例上,并提供负载均衡和会话保持机制,目前有三种工作模式,分别是:用户模式(userspace)、iptables 模式和 IPVS 模式。 |
16.什么是Ingress网络,它是如何工作的?
|
1 |
17.什么是Container(容器)资源监控?
|
1 |
18.Replica Set 和 Replication Controller之间有什么区别?
|
1 2 |
基本没什么太大区别,都是保证在所有时间内,都有特定数量的Pod存在。如果太多了RC/RS就杀死几个,如果太少了RC/RS就会新建几个。和直接创建pod不同的是,RC/RC都会替换掉哪些删除或者被终止的POD. 不同点是,RS支持集合式选择器(selector) |
19.什么是Headless Service?
|
1 |
headless service 是将service的发布文件中的clusterip=none ,不让其获取clusterip , DNS解析的时候直接走pod |
来自QQ大佬
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 |
kube-apiserver 主要负责暴露Kubernetes API,不管是kubectl还是HTTP调用来操作Kubernetes集群各种资源,都是通过kube-apiserver提供的接口进行操作的。 kube-controller-manager 管理控制器负责整个Kubernetes的管理工作,保证集群中各种资源的状态处于期望状态,当监控到集群中某个资源状态不正常时,管理控制器会触发对应的调度操作,主要由以下几部分组成: 节点控制器(Node Controller) 副本控制器(Replication Controller) 端点控制器(Endpoints Controller) 命名空间控制器(Namespace Controller) 身份认证控制器(Serviceaccounts Controller) cloud-controller-manager 云管理控制器是Kubernetes 1.6新加入的组件(组件抽象了一层IaaS平台的接口,具体的实现由各云厂商负责提供),主要负责与基础计算云平台(IaaS)的交互,目前还处于测试开发阶段,我们也还没有使用过该组件。该组件的具体实现包括: 节点控制器(Node Controller) 路由控制器(Route Controller) 负载均衡服务控制器(Service Controller) 数据卷控制器(Volume Controller) kube-scheduler 调度器负责Kubernetes集群的具体调度工作,接收来自于管理控制器(kube-controller-manager)触发的调度操作请求,然后根据请求规格、调度约束、整体资源情况等因素进行调度计算,最后将任务发送到目标节点的kubelet组件执行。 kube-scheduler 可以启动多组,设置不通调度名字,配置自己的调度策略 etcd etcd是一款用于共享配置和服务发现的高效KV存储系统,具有分布式、强一致性等特点。在Kubernetes环境中主要用于存储所有需要持久化的数据。 kube-scheduler 给一个简单自定义策略 --use-legacy-policy-config=true \ --policy-config-file=/apps/kubernetes/config/scheduler-policy-config.json \ scheduler-policy-config.json { "kind" : "Policy", "apiVersion" : "v1", "predicates" : [ {"name" : "PodFitsHostPorts"}, {"name" : "PodFitsResources"}, {"name" : "NoDiskConflict"}, {"name" : "NoVolumeZoneConflict"}, {"name" : "MatchNodeSelector"}, {"name" : "HostName"} ], "priorities" : [ {"name" : "LeastRequestedPriority", "weight" : 1}, {"name" : "BalancedResourceAllocation", "weight" : 1}, {"name" : "ServiceSpreadingPriority", "weight" : 1}, {"name" : "EqualPriority", "weight" : 1} ], "hardPodAffinitySymmetricWeight" : 10 } Node节点组件 kubelet kubelet是Node节点上最重要的核心组件,负责Kubernetes集群具体的计算任务,具体功能包括: 监听Scheduler组件的任务分配 挂载POD所需Volume 下载POD所需Secrets 通过与docker daemon的交互运行docker容器 定期执行容器健康检查 监控、报告POD状态到kube-controller-manager组件 监控、报告Node状态到kube-controller-manager组件 kube-proxy 可以被替代 kube-proxy主要负责Service Endpoint到POD实例的请求转发及负载均衡的规则管理。 kube-proxy本身实际上并不负责请求转发和负载均衡,而时从kube-apiserver获取Service和POD的状态更新,生成对应的DNAT规则到本地的iptabels,最终的转发和负载均衡动作有iptabels实施,所以kube-proxy组件即使出现问题,已经更新到iptabels的转发规则依然能够生效。 |
四、多项选择习题
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 |
这部分问题将包括多项面试问题,这些问题在面试中经常被问到。 Q1。什么是Kubernetes集群中的minions? A.它们是主节点的组件。 B.它们是集群的工作节点。[答案] C.他们正在监控kubernetes中广泛使用的引擎。 D.他们是docker容器服务。 Q2。Kubernetes集群数据存储在以下哪个位置? A.KUBE-API服务器 B.Kubelet C.ETCD [答案] D.以上都不是 Q3。哪个是Kubernetes控制器? A.ReplicaSet B.Deployment C.Rolling Updates D.ReplicaSet和Deployment [答案] Q4。以下哪个是核心Kubernetes对象? A.Pods B.Services C.Volumes D.以上所有[答案] Q5。Kubernetes Network代理在哪个节点上运行? A.Master Node B.Worker Node C.所有节点[答案] D.以上都不是 Q6。 节点控制器的职责是什么? A.将CIDR块分配给节点 B.维护节点列表 C.监视节点的运行状况 D.以上所有[答案] Q7。Replication Controller/ReplicaSet的职责是什么? A.使用单个命令更新或删除多个pod B.有助于达到理想状态 C.如果现有Pod崩溃,则创建新Pod D.以上所有[答案] Q8。如何在没有选择器的情况下定义服务? A.指定外部名称[答案] B.指定具有IP地址和端口的端点 C.只需指定IP地址即可 D.指定标签和api版本 Q9。1.8版本的Kubernetes引入了什么? A.Taints and Tolerations [答案] B.Cluster level Logging C.Secrets D.Federated Clusters Q10。Kubelet 调用的处理检查容器的IP地址是否打开的程序是? A.HTTPGetAction B.ExecAction C.TCPSocketAction [答案] D.以上都不是 |
网络类:
1.ISO/OSI七层模型的分层与作用
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 |
ISO 国际标准化组织 OSI 开放系统互联 7.应用层 为用户提供服务,给用户一个操作界面 (打开windos/linux呈现给用户的界面,就是应用层) 6.表示层 主要做三个方面工作:1.数据提供表示 2.加密 3.压缩 (计算机识别的是二进制,那么图形界面啊图片啊视频啊音频啊要翻译成二进制,这个工作由表示层来完成) 5.会话层 确定是否需要网络传递,如果需要则传递,不需要就保存本地 4.传输层 对报文进行分组(发送),组装(接收) 提供传输协议选择 TCP(传输控制协议):可靠的面向连接的传输协议(可靠,准确,慢) UDP(用户数据报协议):不可靠的面向无连接的数据协议(快,不可靠) 端口封装 差错校验 (IPV4协议规定目前的数据包大小不能大于2的16次方,也就是65535个字节,我们会话层传送的数据包都比这个小吗,不会,到了这一层会将大于规定大小数据包拆开,拆成小于65535的数据包) (收的时候,把这些拆开的数据包按照顺序再组装起来) (TCP慢但是可靠,udp快但是可能丢包) (TCP A 给 B发消息(问三次,所以叫三次握手): A:你在吗? B:我在啊 A:你在吗,我要给你发信了? B:我在啊,你可以发信给我 A:你在吗? B:我在啊 接下来才发送数据,所以他更可靠,数据丢的可能性更小) (UDP A 给 B发消息: 管你在不在我直接就发出去,接着了算你运气,接不上活该 ) tcp更像是打电话,udp更像是发短信 tcp和udp哪个好?都好,看使用场景。 tcp适合对数据稳定性,更可靠。 udp QQ 微信啊 都是使用udp 端口封装:确定源端口和目标端口 差错校验: tcp 三次握手 b发现a发送的这个包是错的,会告诉a你重新再发一个. 如果是udp b发现a发的包是错的,由于b和a没有办法联系,所以b直接就丢弃这个错误包。 3.网络层(典型的设备就是交换机) IP地址编址 (源ip 和 目标ip) 路由选择 静态路由(管理员指定) 动态路由(路由自己判断) 2.数据链路层 MAC地址编址 MAC地址寻址 差错校验 (MAC地址是用来同网段访问的,IP(门牌号) MAC(邮编) 端口(收件人),通过MAC和IP我找到了这台电脑,但是这台电脑上开了很多服务,开了很多端口,你到底要发送到他哪个服务呢,这时候端口的作用就体现出来了) ( 常见的服务端口: web:80 文件传输是:20,21(ftp) SSH :22 telnet:23 smpt:25 DNS :53 DHCP:67,68 TFTP:69 POP3:110 NTP:123 SNMP:161 LDAP:389 HTTPS:443 LDAPS:636 rsync:873 oracle:152 mysql:3306 php-fpm:9000 ) 1.物理层(典型的设备就是网线) 实际数据的传输 电气特性的定义(网线是8根线,哪根线来传输数据?物理层来决定,不是8根线都是传递数据的,第七根第八根白棕线都不传递数据) |
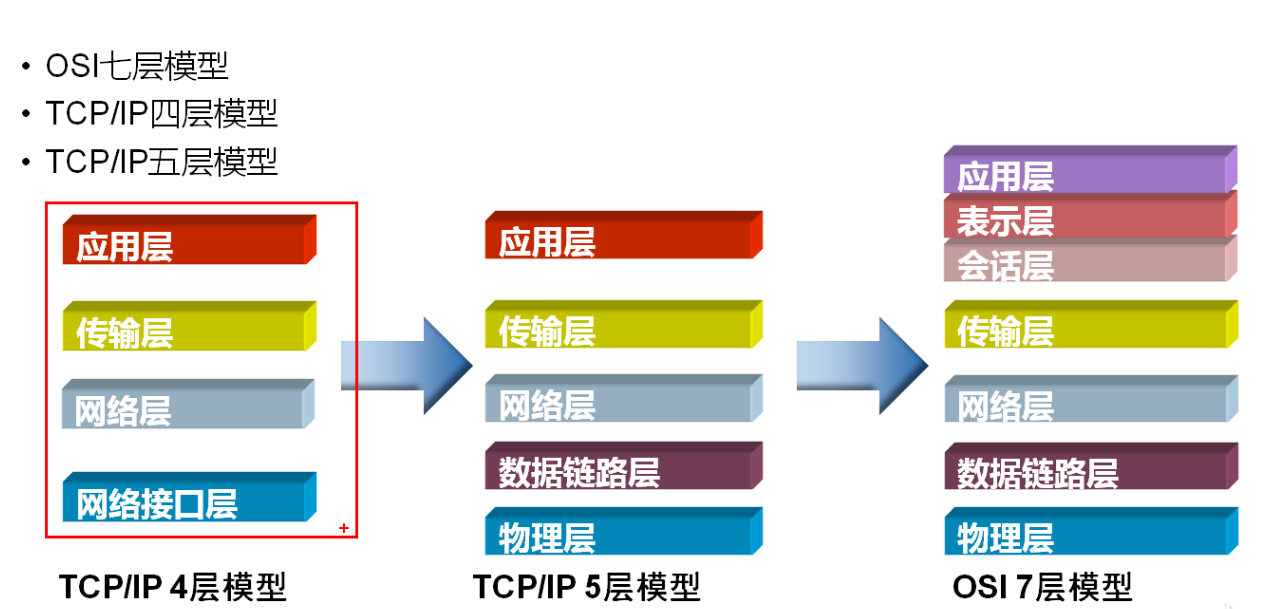
2.TCP/IP 四层模型与作用?
|
1 2 3 4 5 6 |
哪4层: 应用层 (应用层+表示层+会话层) 传输层 网络层 网络接口层 (数据链路层+物理层的合并) 实际是5层。这个层级是上世纪60年代提出的。开发太久远,也没人动过去更改。所以你心里明白是5层就好了。 |
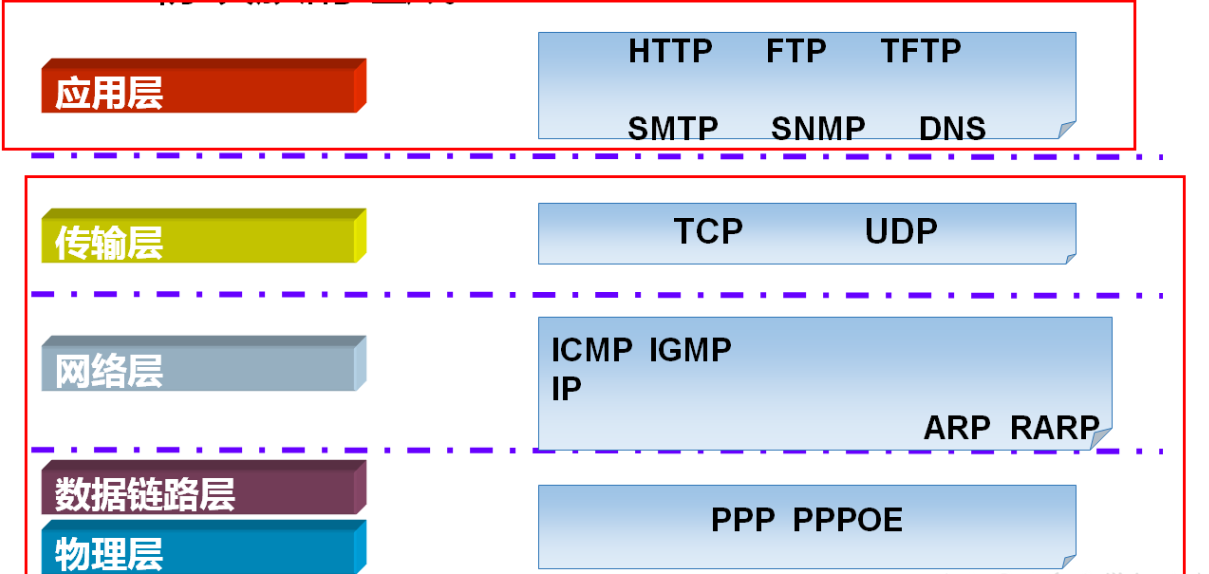
3.TCP协议与UDP协议工作在哪一层,作用是什么?
|
1 |
TCP与UDP协议工作在传输层,作用是传输数据 ,http协议工作在应用层. |
TCP 与UDP 与http的区别
|
1 2 3 |
http:是用于www浏览的一个协议。 tcp:是机器之间建立连接用的到的一个协议。 udp: 是与TCP相对应的协议。它是面向非连接的协议,它不与对方建立连接,而是直接就把数据包发送过去! |
简述TCP三次握手过程
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
考察知识点:TCP协议的原理 和 TCP协议的作用 传输层协议 TCP(传输控制协议):可靠的面向连接的传输协议(可靠,准确,慢) UDP(用户数据报协议):不可靠的面向无连接的数据协议(快,不可靠) A 序列号(32位) (Seq序号) B 确认号(32位) (Ack序号) ACK=Seq+1 A 生产一个32位序列号发送给B B 收到序列号后+1 然后再发给A 这样一个过程就是B告诉A你的信息我收到了,我给你做个标记+1,看到这个标记证明我收到了 标志位:共6个,URG, ACK, PSH ,RST, SYN ,FIN 具体含义如下: URG: 紧急指针 *ACK:确认序号有效 PSH: 接收方应该尽快将这个报文交给应用层 RST: 重置连接 *SYN: 发起一个新连接 (SYN也叫"信"包) *FIN: 释放一个连接 这6个标志位的状态,在每次的会话交互中,只允许有1个标志位状态为1,其他为0,比如SYN为1,其他标志位都为0,就代表SYN要发起这个标志标记的(作用)连接了。 |


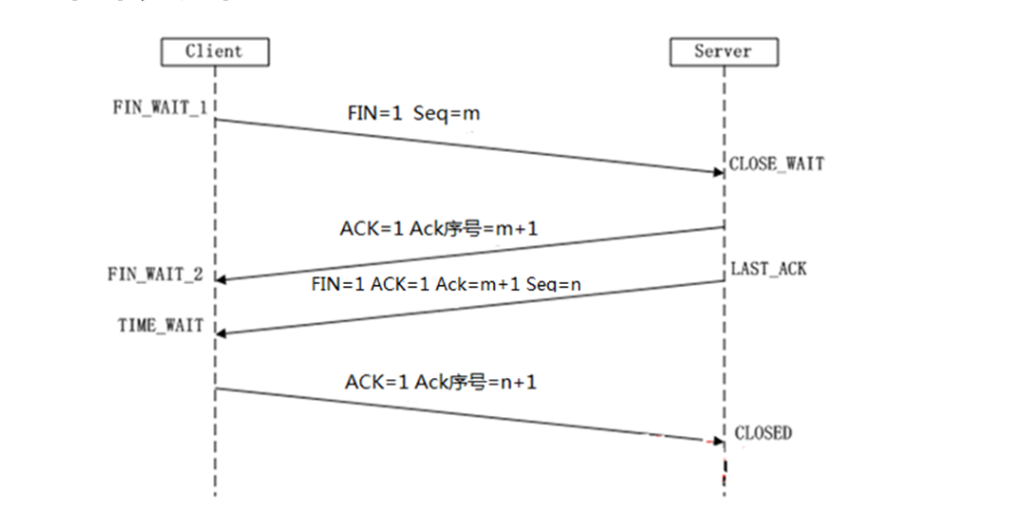
简述Tcp包头的作用
TCP四次挥手

172.22.141.231/26,该ip位于哪个网段?该网段拥有多少个可用ip地址?广播地址是什么?
|
1 2 3 4 5 6 7 8 9 10 11 12 |
考察点: 子网掩码的作用 ip地址与子网掩码划分 网络地址与广播地址的概念 计算方法: 26指的是:三个255.255.255.192 为什么呢,255如果换算成二进制就是11111111 三个255就是24个1 ,后边的192就是11000000 ,换句话说26就是指的子网掩码当中,二进制1的个数。 子网掩码的作用: 子网掩码必须和IP地址成对出现,否则没有意义 子网掩码是用于给IP地址划分网络地址与主机地址的 |

Nginx
nginx location优先级
|
1 2 3 4 5 6 |
在nginx的location和配置中location的顺序没有太大关系。正location表达式的类型有关。相同类型的表达式,字符串长的会优先匹配。 ( = 高于 ^~ 高于 ~* 等于 ~ 高于 / ) = 的优先级最高 ^~ 优先级次之 ~,~* 的优先级一致,次于^~ 普通字符串匹配优先级最低 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
server { listen 80; server_name www.aminglinux.com; root /tmp/123.com; location ^~ '/abc.html' { echo '^~'; } location = '/abc.html' { echo '='; } } 测试命令:curl -x127.0.0.1:80 'www.aminglinux.com/abc.html 结果是:= |
nginx 负载均衡
|
1 2 3 4 5 6 7 8 9 10 11 12 |
upstream backserver { server 192.168.0.14; server 192.168.0.15; } 负载均衡的几种方式: 1.轮询 默认方式 2.weight 权重方式,在轮询策略的基础上指定轮询的几率 3.ip_hash 依据ip分配方式(相同客户端请求一直发送到相同服务器,会话保持) 4.least_conn 将请求发送给后端连接压力最少连接的服务器来分配 5.fair(第三方) 根据后端服务器响应时间长短来分配 6.url_hash(第三方) 依据URL分配方式 |
nginx怎样配置会话保持
|
1 2 3 4 5 6 7 8 9 |
指定负载均衡器按照基于客户端IP的分配方式,这个方法确保了相同的客户端的请求一直发送到相同的服务器,以保证session会话保持。这样每个访客都固定访问一个后端服务器,可以解决session不能跨服务器的问题。 upstream dynamic_zuoyu { ip_hash; #保证每个访客固定访问一个后端服务器 server localhost:8080 weight=2; #tomcat 7.0 server localhost:8081; #tomcat 8.0 server localhost:8082; #tomcat 8.5 server localhost:8083 max_fails=3 fail_timeout=20s; #tomcat 9.0 } |
nginx流量限制
|
1 2 3 4 5 6 7 |
1.Nginx流量限制 实现流量限制由两个指令 limit_rate 和 limit_rate_after 共同完成: 2.Nginx并发限制 limit_conn_zone 语法: limit_conn_zone zone_name $variable the_size 3.Nginx代理数据裤(tcp) 模块名称:--with-stream |
Shell类题目
1.有个test的文本,内容如下,要求将所有的域名截取出来,并统计重复域名出现的次数。
|
1 2 3 4 5 6 7 8 9 |
http://www.shooter.com/cctv/index.html http://www.cmd.com/mmtvc/index.html http://www.cmd5.com/mmtvc/index.html http://www.torcze.com/mmtv/index.html http://www.torcze.com/mmtv/index.html http://www.2345.com/mmt/index.html http://www.2345.com/mmt/index.html http://www.2345.com/mmt/index.html http://www.baidu.com/index.html |
|
1 2 3 4 5 6 7 8 |
答案 cat test | cut -d "/" -f 3| sort | uniq -c | sort -nr 命令解释: cut -d "/" -f 3 #用"/"作为分隔符,截取第3个字段 sort #第一次排序 uniq -c #显示该行重复次数 sort -nr #按照数值从大到小排序 |

2.统计正在连接的IP地址,并按连接次数排序
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
答案: netstat -an | grep ESTABLISHED | awk '{print $5}' | cut -d ":" -f 1 | sort -n | uniq -c | sort -nr TCP端口状态说明 1、LISTENING状态 FTP服务启动后首先处于侦听(LISTENING)状态。 2、ESTABLISHED状态 ESTABLISHED的意思是建立连接。表示两台机器正在通信。 3、CLOSE_WAIT 对方主动关闭连接或者网络异常导致连接中断,这时我方的状态会变成CLOSE_WAIT 此时我方要调用close()来使得连接正确关闭 4、TIME_WAIT 我方主动调用close()断开连接,收到对方确认后状态变为TIME_WAIT。TCP协议规定TIME_WAIT状态会一直持续2MSL(即两倍的分 段最大生存期),以此来确保旧的连接状态不会对新连接产生影响。处于TIME_WAIT状态的连接占用的资源不会被内核释放,所以作为服务器,在可能的情 况下,尽量不要主动断开连接,以减少TIME_WAIT状态造成的资源浪费。 目前有一种避免TIME_WAIT资源浪费的方法,就是关闭socket的LINGER选项。但这种做法是TCP协议不推荐使用的,在某些情况下这个操作可能会带来错误。 5、SYN_SENT状态 SYN_SENT状态表示请求连接,当你要访问其它的计算机的服务时首先要发个同步信号给该端口,此时状态为SYN_SENT,如果连接成功了就变为 ESTABLISHED,此时SYN_SENT状态非常短暂。但如果发现SYN_SENT非常多且在向不同的机器发出,那你的机器可能中了冲击波或震荡波 之类的病毒了。这类病毒为了感染别的计算机,它就要扫描别的计算机,在扫描的过程中对每个要扫描的计算机都要发出了同步请求,这也是出现许多 SYN_SENT的原因。 |
3.使用循环在/demo 目录下创建10个txt文件,要求文件名称由6位随机小写字母和固定字符串(_st) 组成, 例如:pzjdkeg_st
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
系统下有2个特殊系统文件 /dev/random 依赖系统中断生成随机字符串,可以保证数据的随机性,但生成数据慢,并且占用系统资源 /dev/urandom 不依赖系统中断生成随机字符串,生成数据速度块但数据随机性不足(一班建议使用这个) tr命令:可以对来自标准输入的字符进行替换,压缩和删除。它可以从一组字符串中提取出另一组字符串 -c: 取代所有不属于第一字符集的字符 -d: 删除所有属于第一字符集的字符 例如:从输入的文本中,只提取出数字 echo "aa...+1 b2c /* $dd ls 3,45dkgs" | tr -dc '0-9 \n' [root@localhost demo]# echo "aa...+1 b2c /* $dd ls 3,45dkgs" | tr -dc '0-9 \n' 1 2 345 执行 tr -dc 'A-Za-z0-9' < /dev/urandom 从随机字符中只提取数字与大小写字母 答案脚本: #!/bin/bash if [ ! -d /root/demo ];then mkdir -p /root/demo fi cd /root/demo for (( i=1;i<10;i++ )) do filename=$(tr -dc 'A-Za-z0-9' < /dev/urandom | head -c 6) touch "$filename"_gg.txt done |
4.生成随机数
|
1 2 3 4 5 6 |
系统变量 $RANDOM echo $RANDOM 扩展:生成1000以内的 echo $(($RANDOM%1000)) #1000就是1000以内,1000000就是十万以内 |

5.批量检测网站是否可以访问
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
首先将网站url统计存入文件或者数组 web=(www.baidu.com wwww.123.com) shell数组中以空格隔开 然后逐行读取 利用curl命令逐一访问域名,通过返回信息,来判断网站当前情况 curl -o 将命令输出保存到文件 curl -s slient模式不输出任何内容 curl -w 按指定格式输出内容,例如:-w %{http_code}:输出http状态码 一般网站200,302是代表正常 curl --connect-timeout:连接超时时间 循环检测主要语句: curl -o /dev/null -s --connect-timeout 5 -w '%{http_code}' http://www.yoyoask.com | grep -E "200|302" grep -E 让它支持扩展正则 | 或者竖杠是正则 |

6.linux下用shell删除三天前或者三天内的文件
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
ind / -amin -30 -ls # 查找在系统中最后30分钟访问的文件 find / -atime -2 -ls # 查找在系统中最后48小时访问的文件 find / -mmin -10 -ls # 查找在系统中最后10分钟里修改过的文件 find / -mtime -1 -ls # 查找在系统中最后24小时里修改过的文件 find / -cmin -10 -ls # 查找在系统中最后10分钟里被改变状态的文件 find / -ctime -1 -ls # 查找在系统中最后24小时里被改变状态的文件 #查找三天前的文件 /usr/bin/find /demo/* -mtime +3 -ls #查找三天前的文件个数 /usr/bin/find /demo/* -mtime +3 | wc -l #删除三天以内的文件 /usr/bin/find /demo/* -mtime -3 -delete #删除10天前的所有文件 find /tmp/* -type f -mtime +10 -exec rm {} \; #查找10天前的所有文件 find /tmp/* -type f -mtime +10 -exec ls -l {} \; 删除awk过滤的日期文件 rm -rf `ll | awk '{if("1"==$7) print $9}'` |
7.找出修改时间为3天前的文件,并移动到data目录下
|
1 2 3 |
find /root/demo/*.txt -ctime -3 -exec mv {} /root/data/ \; or find /root/data/ -type f -atime -20 -exec mv {} /root/demo/ \; |
8.查找某个目录下包含某个关键词的文件(文件包含)
|
1 2 3 4 5 |
xargs: find / -type f -name "*.log" | xargs grep "hello" #从根目录开始查找所有扩展名为.log的文本文件,并找出包含”ERROR”的行 find . -name "*.php" | xargs grep "thermcontact" #从当前目录开始查找所有扩展名为.php的文本文件,并找出包含"thermcontact" |
9.批量修改目录下文件名为源文件名+日期格式
|
1 2 3 4 5 6 7 |
for file in $(ls|grep -E "*.txt") do cname=$(echo "$file" | cut -d "." -f 1) dat=$(date "+%Y-%m-%d") newfilename="${cname}_${dat}.txt" mv $file $newfilename done |

系统管理类
1.DHCP是什么,他是怎么工作的。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
动态主机配置协议,局域网的网络协议。指的是由服务器控制一段IP地址范围,客户机登录服务器时就可以自动获得服务器分配的IP地址和子网掩码。 dhcp client DHCP discover dhcp的服务器会规定一个ip地址范围,然后新到dhcp客户机启动的时候会用广播向局域网内喊一声,我叫什么我的MAC是xxxx,谁能给我分配个地址。你们谁是dhcp服务器,如果你们有人是的话,请给我分配一个合理的ip地址。 dhcp server DHCP office(只有dhcp服务器会响应,其他人都不会响应) dhcp server听到这个广播后会为这个mac地址的人,找一个合理的可用的IP地址,放到office包中,并且把这个office包广播出去。只不过这个广播上加了刚才请求人的mac地址。(那个请求的人mac地址谁xxx的人,我给你回了个office包,你收一下) dhcp client DHCP request 然后客户端回在局域网内广播,刚才那个ip是xxx的dhcp server的机器,你给我分配的ip,我要用。 dhcp server (ACK/NAK) dhcp server 这时候回复说,好既然你确定要用这个ip,那我跟你确定一下租约。 还有另一种情况NAK 因为服务器office发送过去,然后客户端request这个请求时间可能过长,有可能在这个时间别的机器拿走了刚才确定的ip,这时候dhcp server就会返回NAK,对不起,你刚才确定要用的那个ip已经被别人用了。 |
2.DHCP续租过程
|
1 2 3 4 5 6 7 8 9 |
dhcpIP默认租约时间为120分钟,这个可以自行设置。 当dhcp client 租用server ip时间过了一半了,就要开始续租了。续租的过程是不需要广播参与的,因为大家都知道对方ip了。、 如果dhcp client 无法找到dhcp server服务器地址,它就会从tcp/ip 的B类地址169.254.0.0/16中挑选一个IP地址,作为自己的临时IP地址,然后继续每个5分钟,尝试与dhcp服务器进行通讯 一旦取得联系,则客户机放弃自动配置的临时IP地址,而使用DHCP服务器分配的IP地址 dhcp客户机收到dhcp服务器回应的ack报文后,通过地址冲突检测(arp) 发现server分配的地址冲突或者其他原因不可用,则发送DECLINE报文,通知服务器所分配的IP地址不可用。 还有一种特殊情况,如果2个人ip冲突,后一个冲突的人的电脑也会从tcp/ip 的B类地址169.254.0.0/16中挑选一个IP地址,作为自己的临时IP地址. |
3.FTP 主动模式和被动模式
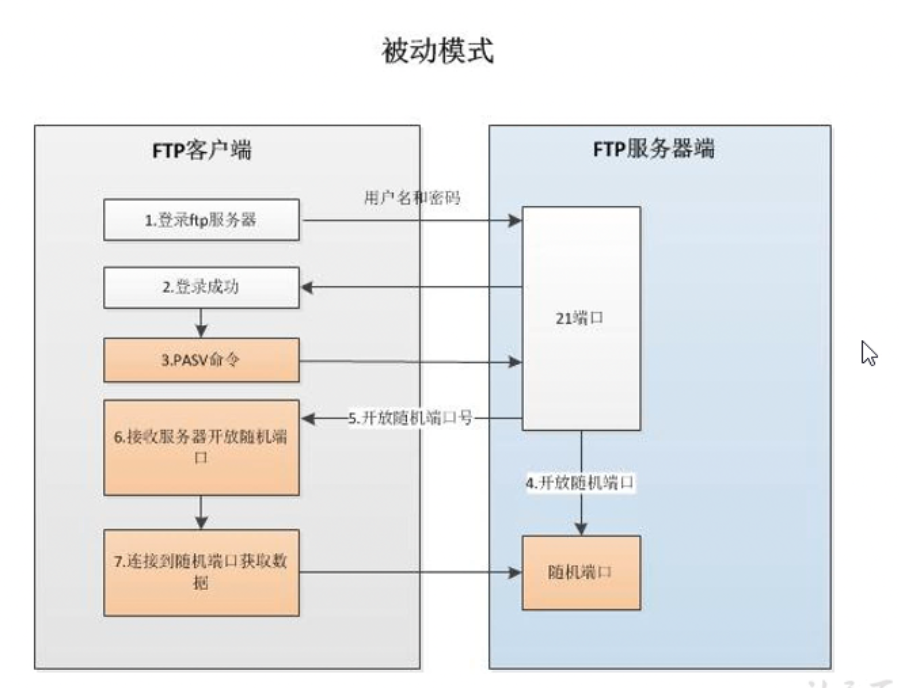
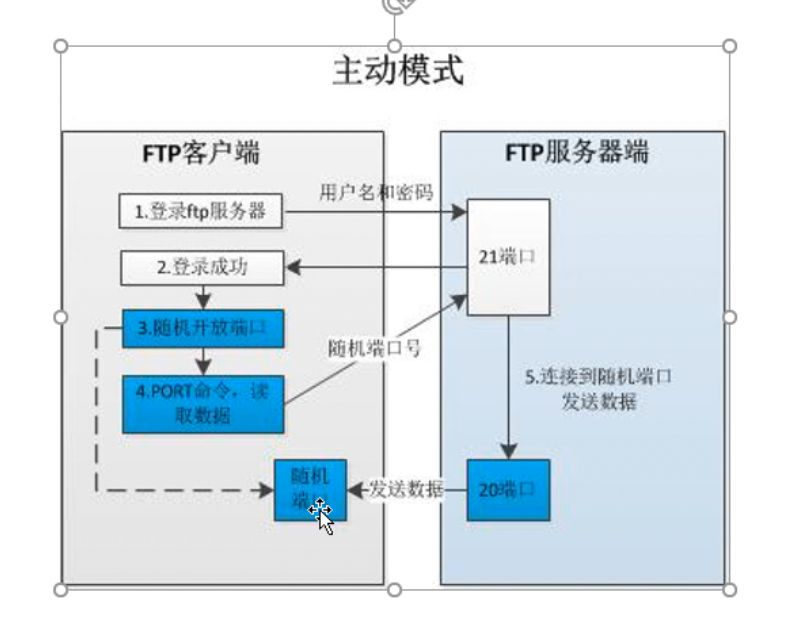
|
1 |
当ftp是被动模式的时候,它与所有客户端建立的连接的端口都不相同 |
4.集群中如何保证服务器时间误差最小
|
1 2 3 |
1.可以自己搭建时间服务器 然后使用ntpdate 同步时间服务器ip地址 2.自动同步时间,写入计划任务 |
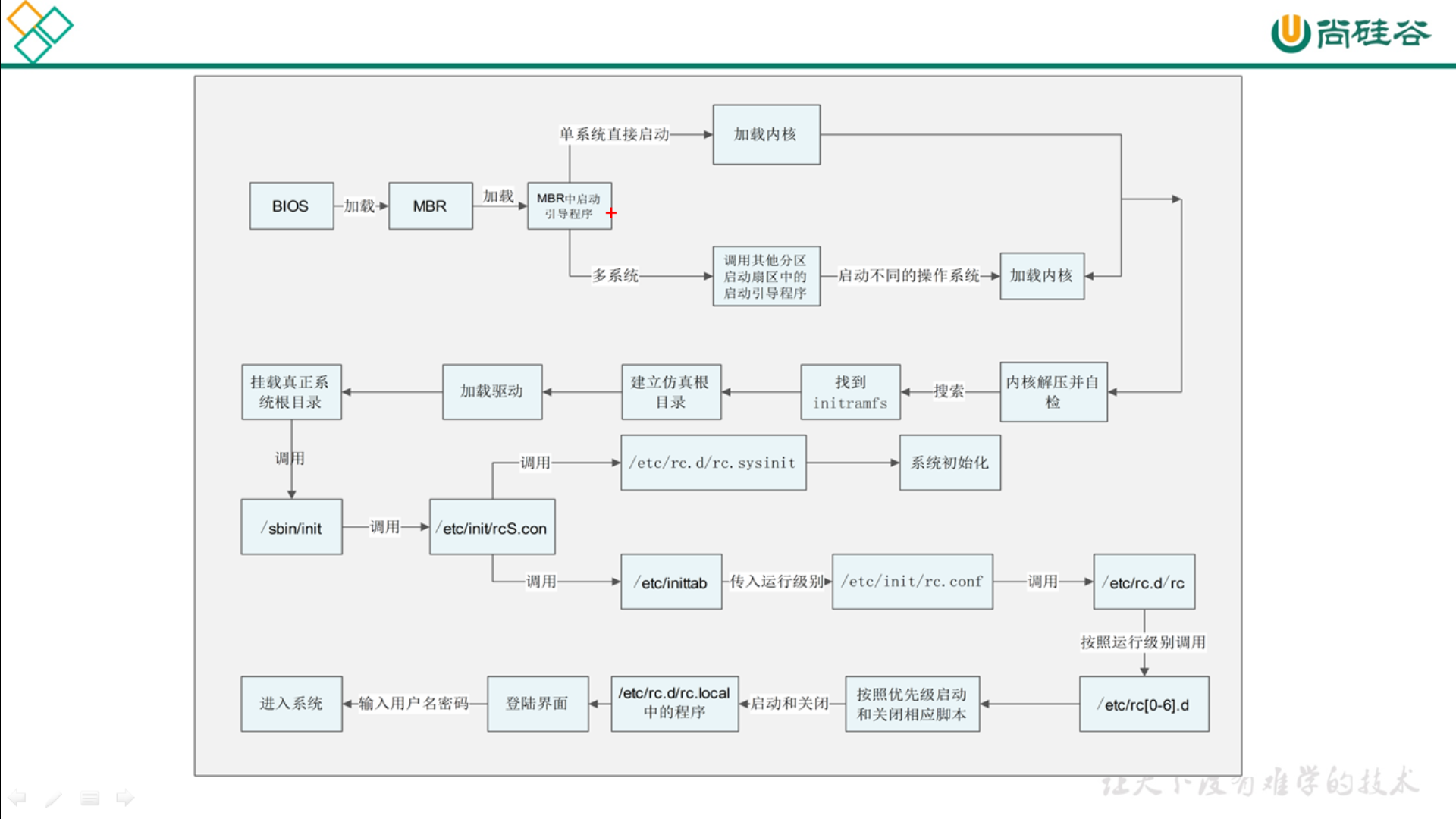
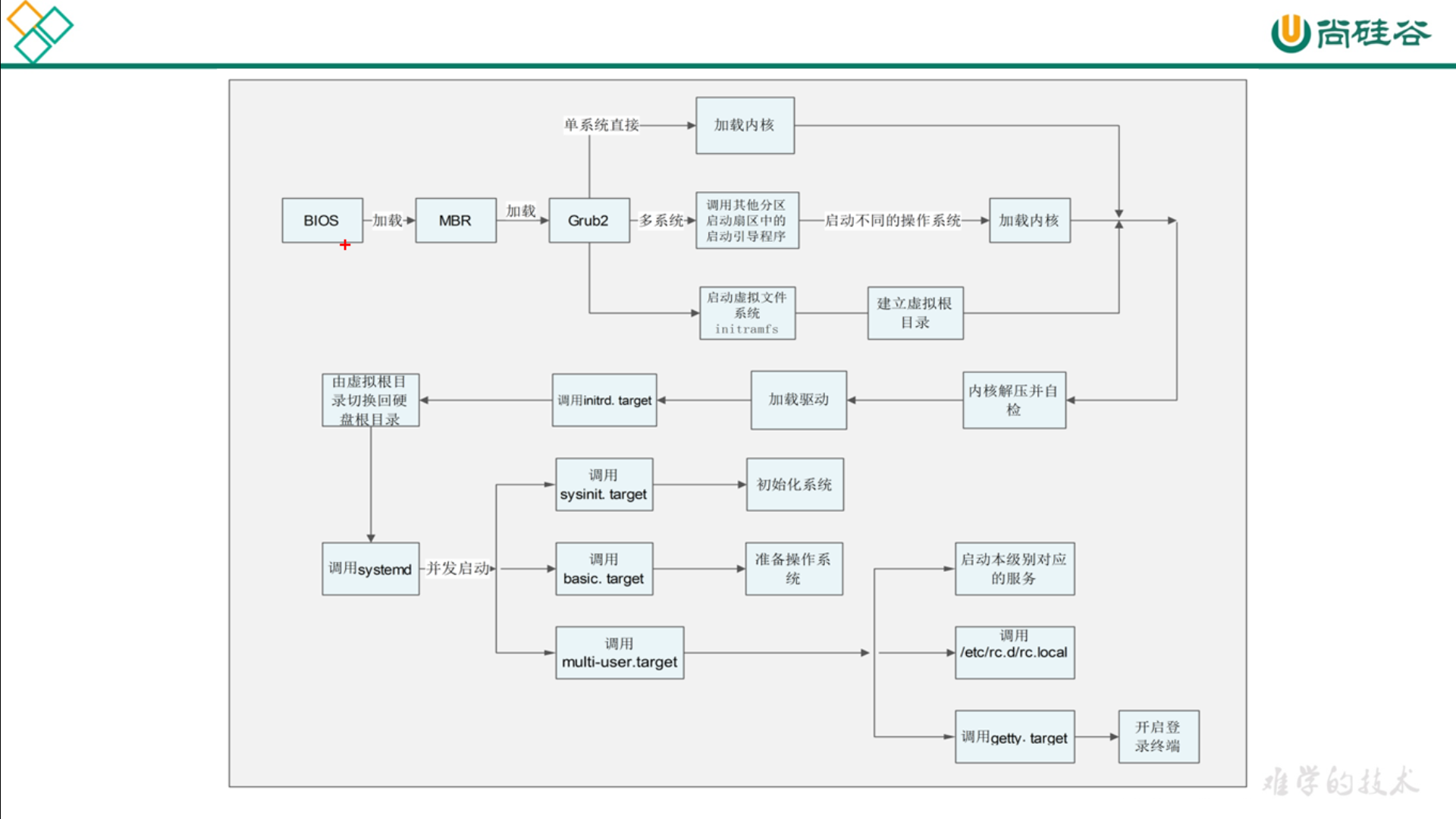
5. 简要概述linux系统启动步骤
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
1.开机BIOS自检 2.MBR引导 3.grub引导菜单 4.加载内核kernel 5.启动init进程 6.读取inittab文件,执行rc.sysinit,rc等脚本 7.启动mingetty,进入系统登陆界面 |
JVM调优
|
1 2 3 4 5 6 7 8 9 10 |
xms初始堆大小,默认是物理内存的1/64 Xmx:最大堆大小,默认是物理内存的1/4 一般项目加个xms和xmx参数就够了。 JVM调优大部分是调GC参数, GC参数主要关注这几点: 1.最大堆和最小堆大小 2.GC算法 3.新生代(年轻代)大小,XX JVM调优工具 jps 个人建议:GC日志:程序启动时用 -XX:+PrintGCDetails 和 -Xloggc:/data/jvm/gc.log 可以在程序运行时把gc的详细过程记录下来,或者直接配置“-verbose:gc”参数把gc日志打印到控制台,通过记录的gc日志可以分析每块内存区域gc的频率、时间等,从而发现问题,进行有针对性的优化。 |
Mysql类
1.如何赋值MySQL root用户访问某个库的权限
|
1 2 3 4 5 6 7 8 9 |
grant all privileges on 想授权的数据库.* to 'user1'@'%'; all 可以替换为 select,delete,update,create,drop GRANT ALL PRIVILEGES ON *.* TO 'shooter'@'%' IDENTIFIED BY '123456' WITH GRANT OPTION; WITH GRANT OPTION:被授予的用户也可把此对象权限授予其他用户或角色 #查看用户权限 show grants for 'shooter'@'%'; |
2.Mysql MGR(生产断电)
|
1 2 3 |
断电宕机会造成binlog丢失 1.跳过GTID方式解决 清除从节点的gtid,查看主节点的gtid,然后设置从节点的gtid_purged何主节点一致 |
3.Mysql MGR原理
|
1 2 3 |
MGR由若干个节点共同组成一个复制组,一个事务的提交,必须经过组内大多数节点(N / 2 + 1)决议并通过,才能得以提交。就是说当你提交一个事物先到达master,master然后使用广播将这个事物广播给其他从库节点,从库节点反馈他数据一致性情况,也就是检测数据冲突,如果数据一致性没问题,好,大家一起提交。如果有某个节点存在问题,则直接放弃该事物。 主从复制原理 主从复制,一主多从,主库提供读写功能,从库提供只读功能。当一个事务在master 提交成功时,会把binlog文件同步到从库服务器上落地为relay log给slave端执行 |
4.RabbitMQ重复消费
|
1 2 |
<1>. 保证消费者幂等性,重复消费也没有关系。(token)(设计一个去重表) <2>. 消息定向消费,并且记录,过滤重复消息。 |
5.Spring Cloud
|
1 2 3 4 5 6 |
Eureka:服务治理组件,包含服务注册与发现 Hystrix:容错管理组件,实现了熔断器 Ribbon:客户端负载均衡的服务调用组件 Feign:基于Ribbon和Hystrix的声明式服务调用组件 Zuul:网关组件,提供智能路由、访问过滤等功能 Archaius:外部化配置组件 |
6.Redis持久化几种方式(2种RDB和AOF)
|
1 2 |
一种是RDB持久化(原理是将Reids在内存中的数据库记录定时dump到磁盘上的RDB持久化) 一种是AOF(append only file)持久化(原理是将Reids的操作日志以追加的方式写入文件)。 |
7.Redis哨兵模式和高可用有什么区别
|
1 2 3 4 |
主节点存活检测、主从运行情况检测、自动故障转移 (failover)、主从切换。Redis 的 Sentinel 最小配置是 一主一从。 通过ping命令来检查节点状态 每个 Sentinel 以 每秒钟 一次的频率,向它所知的 主服务器、从服务器 以及其他 Sentinel 实例 送一个 PING 命令 如果一个 实例(instance)距离 最后一次 有效回复 PING 命令的时间超过 down-after-milliseconds 所指定的值,那么这个实例会被 Sentinel 标记为 主观下线 |
网络类
1.筛选出http访问连接
|
1 |
netstat -an | grep ESTABLISHED | wc -l |
iptables
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
增加/删除一条规则: 添加一条规则到尾部: [root@test ~]# iptables -A INPUT -s 192.168.1.5 -j DROP 再插入一条规则到第三行,将行数直接写到规则链的后面: [root@test ~]# iptables -I INPUT 3 -s 192.168.1.3 -j DROP 查看所有规则 iptables -nL --line-number -A/-D 表示增加或删除一条规则 -I : 表示插入一条规则 -p : 指定协议(tcp、udp、icmp) --dport 和-p一起使用,指定目标端口 (使用dport必须使用-p指定协议) --sport 和-p一起使用,指定源端口 (使用dport必须使用-p指定协议) -s 表示指定源IP -d 表示指定目标ip -j 后面加动作: (1)ACCEPT 放行 (2)DROP 丢掉 (3)REJECT 拒绝包 -i 指定网卡 (DROP 丢掉包 和 REJECT 拒绝包 :效果一样,DROP 丢掉包,直接把包丢弃;REJECT 拒绝包 :分析过再拒绝) 删除之前添加的规则 iptables -A INPUT -s 192.168.1.5 -j DROP 有时候要删除的规则太长,删除时要写一大串,既浪费时间又容易写错,这时我们可以先使用–line-number找出该条规则的行号,再通过行号删除规则。 iptables -nv --line-number 删除第二行规则 [root@test ~]# iptables -D INPUT 2 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
-A INPUT -p tcp -m state --state NEW -m tcp --dport 80 -j ACCEPT -A INPUT -p tcp -m state --state NEW -m tcp --dport 55429 -j ACCEPT -m state --state {NEW,ESTATBLISHED,INVALID,RELATED} 指定检测那种状态 iptables -A INPUT -p tcp -m state --state NEW,ESTABLISHED -j ACCEPT iptables -A OUTPUT -p tcp -m state --state NEW,ESTABLISHED -j ACCEPT -m multiport 指定多端口号 --sport --dport --ports iptables -A INPUT -p tcp -m multiport --dport 22,80,8080 -j ACCEPT iptables -A OUTPUT -p tcp -m multiport --sport 22,80,8080 -j ACCEPT -m iprange 指定IP段 --src-range ip-ip --dst-range ip-ip iptables -A INPUT -p tcp -m iprange --src-range 100.0.0.0/24 --dport 80 -j ACCEPT iptables -A OUTPUT -m connlimit 连接限定 --comlimit-above # 限定大连接个数 -m limit 现在连接速率,也就是限定匹配数据包的个数 --limit 指定速率 --limit-burst # 峰值速率,最大限定 -m string 按字符串限定 --algo bm|kmp 指定算法bm或kmp --string "STRING" 指定字符串本身 |
1.如何设置只允许远程用户访问本机的80端口
2. 写一个linux脚本,实现判断192.168.1.0/24 网络里,当前在线ip有哪些,能ping通则认为在线
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
#!/bin/bash IP=1 while [ $IP -le 5 ]; do ping -c 2 -w 2 192.168.1.$IP &>/dev/null STRING=$? # if ping -w 2 -c 2 192.168.3.$IP &>/dev/null;then if [ $STRING -eq 0 ];then echo -e "\033[32;40m192.168.1.$IP is up.\033[0m" else echo -e "\033[31;40m192.168.1.$IP is down.\033[0m" fi let IP=$IP+1 done |
权限
1.赋予其他用户demo.txt只读权限
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
chmod、u、x、+、a、o、g分别代表什么呢 u 代表用户 x代表执行权限 g 代表用户组. o 代表其他. a 代表所有. + 表示增加权限 chmod u+x file.sh 就表示对当前目录下的file.sh文件的所有者增加可执行权限。。。 这意味着chmod u+x somefile 只授予这个文件的所属者执行的权限 而 chmod +x somefile 和 chmod a+x somefile 是一样的 chmod a+x file.sh 表示对当前目录下的file.sh文件,所有人都拥有可执行权限 |
2./etc/rc.d/rc.local自己增加的指令不能启动的问题的方法
|
1 2 3 4 5 6 7 8 9 |
有时我们自己在/etc/rc.d/rc.local里面增加的随机器启动的脚本和指令总是不能自动加载和启动。 机器启动后手动执行脚本又能成功,经常被搞得晕头转向的。 最近我经过1天的辛苦测试和查找资料,终于解决了这问题,解决方式如下,/etc/rc.d/rc.local文件的文件头是#!/bin/sh ,我们把这修改成#!/bin/sh -x,这样系统启动后就会把/etc/rc.d/rc.local里面的指令或脚本不能执行的日志写入/var/log/messages ,我们查看messages文件内容就知道具体的问题出在哪里了 或者查看 tail -f /var/log/boot.log 在rc.local 文件结尾必须写 exit 0 否则一部分脚本不会被正确执行 |
3.清理目录下空文件夹
|
1 |
find . -type d -empty -exec rm -rf {} \; |

新题补充
|
1 2 3 4 5 6 7 8 9 10 11 |
1.K8s服务报错,不论报什么错,说说你的拍错思路 2.使用k8s如何发布项目到容器里 4.nginx 503 504出错,怎么排查 5.日志筛选定时清除怎么做 6.如何更新k8s生产环境 要考的证书 阿里云ACP认证 k8s cke认证 华为hcie |
加速镜像下载:
|
1 |
https://github.com/uber/kraken |
|
1 |
- 本文固定链接: https://www.yoyoask.com/?p=3115
- 转载请注明: shooter 于 SHOOTER 发表