前言:
随着项目需求的不断增大,访问量不断增多,单主模式的集群方案在很多公司已经没有生存空间,高可用已经成为常态。k8s也不例外,今天说说k8s集群部署。k8s集群部署非常简单。因为k8s已经帮我们做了很多事情,我们需要做的只是实现他的apiserver高可用。
下面图是个人理解。有不同声音的朋友请留言
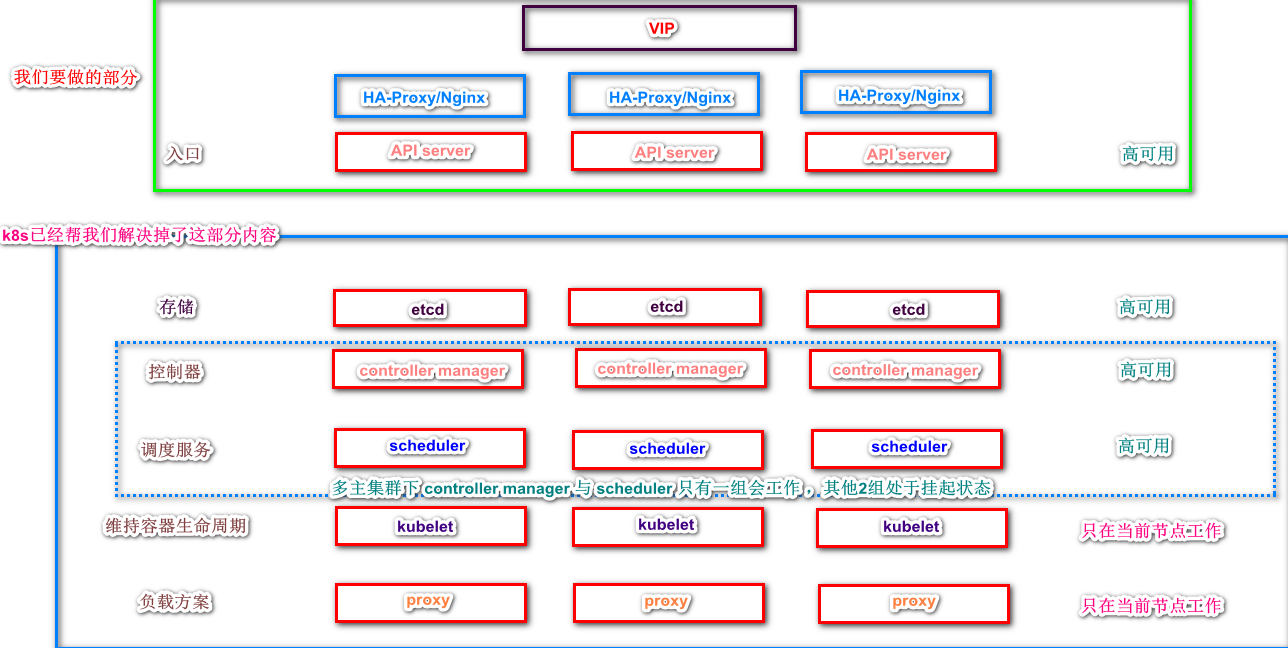
- etcd 存储 ,一般是会放在集群内部托管,多主集群状态下会实现集群化扩展,自动满足高可用。
- controller manager 与 scheduler 对于k8s集群来说只会运行一个,其他都是挂起状态
- kubelet 与 proxy 都是集群内部应用 只在当前节点工作,所以不需要高可用。
k8s已经将集群这一部分的高可用功能帮我们解决掉了,如上图所示,我们需要做的就是为入口apiserver设置高可用。
我们在API server 之前加一个负载调度器,或者nginx ,或者haporxy。需要注意的是调度器直接访问的是节点,而非api server
国内有个apiserver 叫睿云 ,对于睿云来说有个叫breeze的k8s部署工具。他是基于kubeadm来实现的,并且他通过keepalived和HA-poryx来实现高可用,并且他用镜像将2个应用封装了起来。使用起来非常方便(部署结构如上图所示)
准备工作
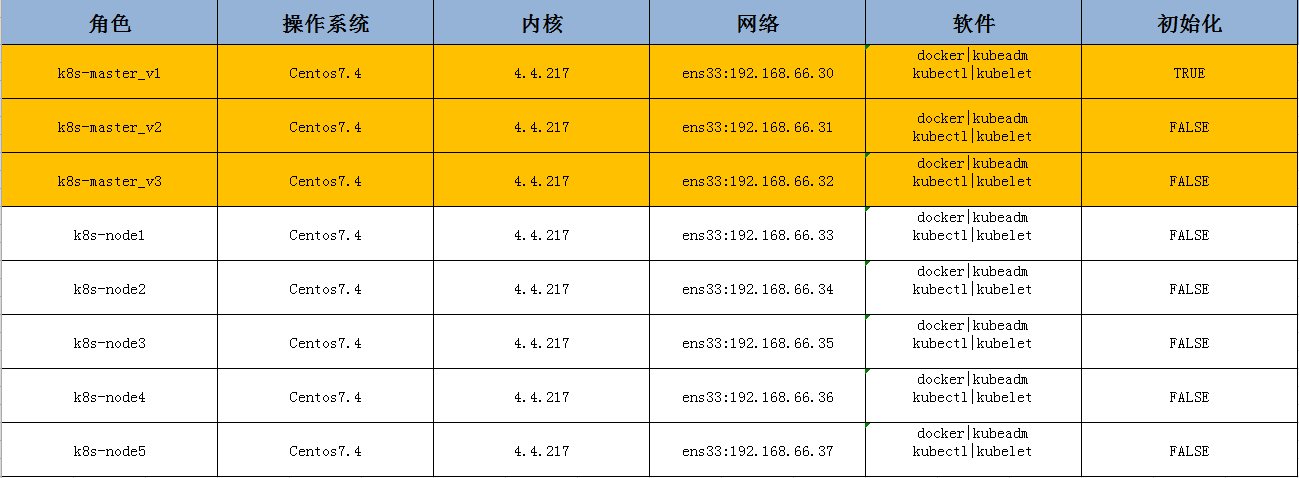
我们打算,用三台机器做主节点,其余5台做工作节点,具体如下:
下面开始实操
这里很抱歉,我原以为我本机可以跑这么多虚拟机,结果只能跑三台虚拟机(太卡),所以我只能演示安装三台主,工作节点就不演示了,主节点创建完后工作节点加入即可。工作其实没什么难度。
1.初始化集群环境(所有节点)
系统初始化请看这篇文章,有详细介绍。 传送门
2.部署安装(所有节点)
(1). kube-proxy开启ipvs的前置条件
|
1 2 3 4 5 6 7 8 9 10 11 |
modprobe br_netfilter cat > /etc/sysconfig/modules/ipvs.modules <<EOF #!/bin/bash modprobe -- ip_vs modprobe -- ip_vs_rr modprobe -- ip_vs_wrr modprobe -- ip_vs_sh modprobe -- nf_conntrack_ipv4 EOF |
|
1 |
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4 |
(2). 安装 Docker 软件
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
yum install -y yum-utils device-mapper-persistent-data lvm2 yum-config-manager \ --add-repo \ http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo yum update -y && yum -y install docker-ce ## 创建 /etc/docker 目录 mkdir /etc/docker # 配置 daemon. cat > /etc/docker/daemon.json <<EOF { "exec-opts": ["native.cgroupdriver=systemd"], "log-driver": "json-file", "log-opts": { "max-size": "100m" }, "insecure-registries":["https://hub.atshooter.com"] } EOF #"insecure-registries":["https://hub.atshooter.com"] 这句是harbor私有仓库安全认证域名.对应你的harbor仓库,没有私有仓库的自己去创建,这里不做赘述 |
|
1 2 3 4 |
mkdir -p /etc/systemd/system/docker.service.d # 重启docker服务 加入开机启动 systemctl daemon-reload && systemctl restart docker && systemctl enable docker |
(3). 组件安装:
- kubeadm 初始化工具
- kubectl 命令行管理工具
- kubelet 跟dokcer交互创建容器
#注意下下面这个脚本,可能行显示的时候么有对齐,自行调整 ,编辑器的原因
|
1 2 3 4 5 6 7 8 9 10 |
cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=0 repo_gpgcheck=0 gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF |
|
1 2 3 |
yum -y install kubeadm-1.15.1 kubectl-1.15.1 kubelet-1.15.1 systemctl enable kubelet.service |
(3.)安装睿云的keepalive 和 Ha-proxy并且导入高可用所需其他镜像,为后续做准备
安装前我们先导入一下高可用所需镜像(kuberadm在初始化我们的云服务器之前会从google的云服务器pull镜像,这个镜像还是比较大的,而且速度比较慢,并且她还需要一个科学上网的东东存在,如果你有ssr这个科学上网东西,那没问题,要是你没有呢,所以我们事先已经打包好了这写要用到的镜像)
|
1 2 |
链接:https://pan.baidu.com/s/1dmgBaf58LyIeXaDU74sYJQ 提取码:snhl |
下载好后导入镜像(三个主节点都需要导入,三台主节点都需要如下操作并启动)
|
1 2 3 4 5 6 7 |
#将压缩包目录下的kubeadm-basic.images.tar.gz 解压 tar -zxvf kubeadm-basic.images.tar.gz #移动压缩包目录下的镜像文件到 kubeadm-basic.images 文件下 mv flannel.tar haproxy.tar haproxy.tar kubeadm-basic.images/ #修改load-images.sh 将镜像目录路径替换为实际所在目录 chmod a+x load-images.sh ./load-images.sh |
导入完成后查看镜像,共计10个

<1>.解压start.keep.tar.gz
|
1 2 3 4 5 6 7 |
#修改解压data目录下的haproxy.cfg文件 cd data/lb/ vim etc/haproxy.cfg 修改server rancher01 192.168.66.30:6443 为你自己主机器的ip 这里haproxy.cnf文件里 当前只先配置一个ip,因为如果多个ip当其他主节点加入的时候,如果找不到第一个节点可能就会加入到他本身,所以目前只配置一个 |
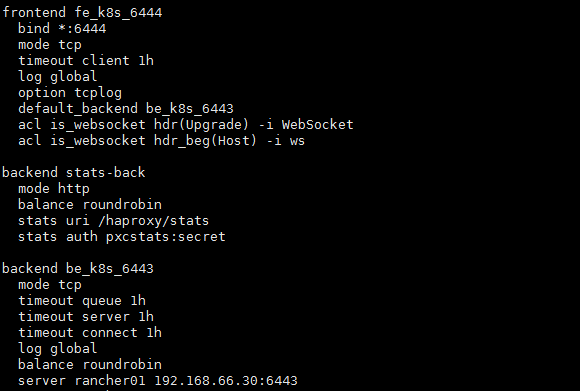
修改完保存后
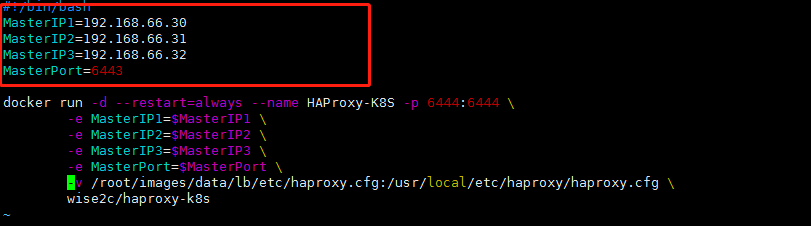
修改 start-haproxy.sh 文件(修改为你的三台主ip)
|
1 2 |
#修改完后保存,启动 ./start-haproxy.sh |
<2>.修改 start-keepalived.sh
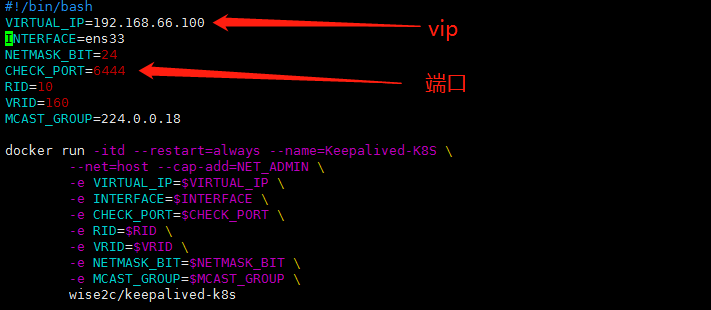
|
1 2 3 4 5 |
1.我当前修改keepalived的vip为,192.168.66.100 2.我当前keepalived的端口保持默认6444 #修改完成后保持,启动 ./start-keepalived.sh |
你可以将改写好的这些文件,整包打包,传送到其他机器,直接执行启动
(4).初始化主节点(三台主节点任意选一台为master,这里我使用66.30这台)
<1>.配置 kuberadm-config.yaml 文件(这里与集群安装稍微有不一样)
|
1 2 3 4 5 |
mkdir -p /root/install-k8s/etc/ cd /root/install-k8s/etc/ #将kuberadm的配置文件打印到默认的kuberadm-config.yaml文件中 kubeadm config print init-defaults > kubeadm-config.yaml |
<2>.编辑kubeadm-config.yaml文件
|
1 |
vim kubeadm-config.yaml |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
#修改文件内容如下: localAPIEndpoint: advertiseAddress: 192.168.66.30 #修改为当前的服务器节点地址 controlPlaneEndpoint: "192.168.66.100:6444" #添加vvip kubernetesVersion: v1.15.1 #修改为当前版本号 networking: podSubnet: "10.244.0.0/16" #这里要添加这一行,为什么呢?默认情况下我们会安装一个Flanneld的插件,去给我们实现覆盖网络他的默认的pod net网段就是这个,如果这个网段不一致,后期你要去配置文件修改,我们先提前统一写好 serviceSubnet: 10.96.0.0/12 # #然后在最后一行添加如下代码,作用是把默认的调度模式改为ipvs --- apiVersion: kubeproxy.config.k8s.io/v1alpha1 kind: KubeProxyConfiguration featureGates: SupportIPVSProxyMode: true mode: ipvs #修改默认调度模式为ipvs |
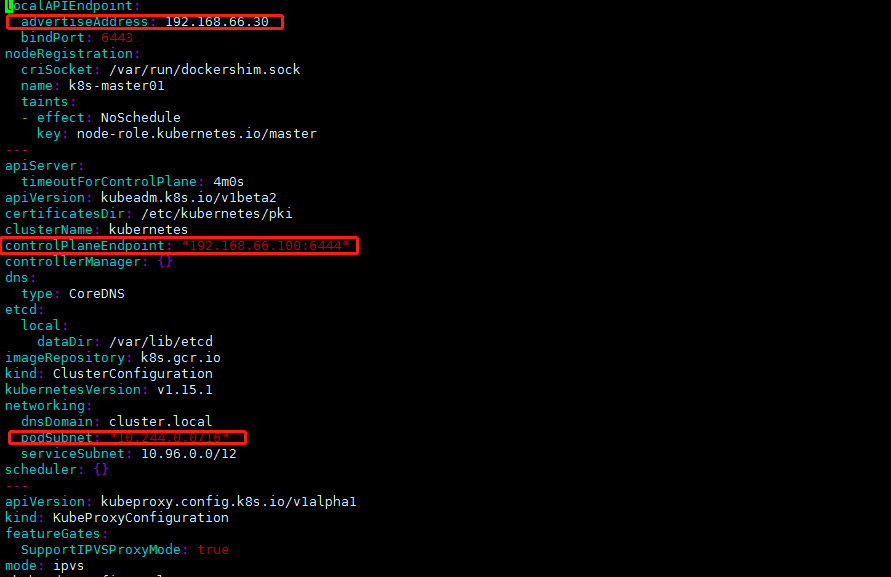
完整配置文件如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
apiVersion: kubeadm.k8s.io/v1beta2 bootstrapTokens: - groups: - system:bootstrappers:kubeadm:default-node-token token: abcdef.0123456789abcdef ttl: 24h0m0s usages: - signing - authentication kind: InitConfiguration localAPIEndpoint: advertiseAddress: 192.168.66.30 bindPort: 6443 nodeRegistration: criSocket: /var/run/dockershim.sock name: k8s-master01 taints: - effect: NoSchedule key: node-role.kubernetes.io/master --- apiServer: timeoutForControlPlane: 4m0s apiVersion: kubeadm.k8s.io/v1beta2 certificatesDir: /etc/kubernetes/pki clusterName: kubernetes controlPlaneEndpoint: "192.168.66.100:6444" controllerManager: {} dns: type: CoreDNS etcd: local: dataDir: /var/lib/etcd imageRepository: k8s.gcr.io kind: ClusterConfiguration kubernetesVersion: v1.15.1 networking: dnsDomain: cluster.local podSubnet: "10.244.0.0/16" serviceSubnet: 10.96.0.0/12 scheduler: {} --- apiVersion: kubeproxy.config.k8s.io/v1alpha1 kind: KubeProxyConfiguration featureGates: SupportIPVSProxyMode: true mode: ipvs |
接下来通过指定yaml文件,进行初始化安装,以及自动颁发证书
|
1 2 3 4 5 6 |
#执行下面语句开始初始化安装 kubeadm init --config=kubeadm-config.yaml --experimental-upload-certs | tee kubeadm-init.log 解释: --experimental-upload-certs (#让其他节点自动颁发证书,1.13版之后才有这个命令,高可用非常有用) tee kubeadm-init.log (#把所有安装信息都写入到kuberadm-init.log中) |
初始化完成后,你会看到
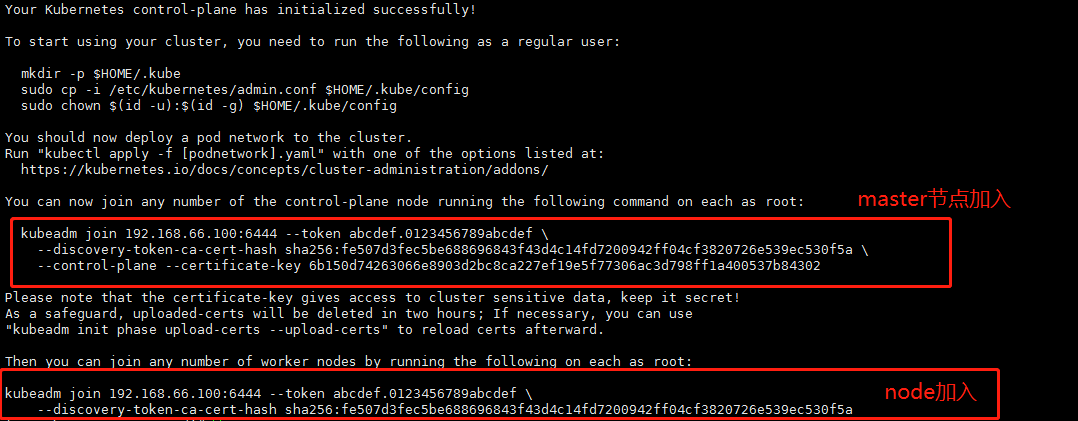
上面的是,多主模式下其他主节点加入集群使用,下面是工作节点加入集群使用。
然后执行下安装后的提示信息(然后把这些该创建的创建 该拷贝的拷贝):
|
1 2 3 |
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config #拷贝集群管理配置文件 sudo chown $(id -u):$(id -g) $HOME/.kube/config #授权 |
然后我们去看 /root/.kube/config文件 就会发现 server: https://192.168.66.100:6444
到此主节点配置初始化完成,我们使用命令查看一下节点
|
1 2 3 4 |
kubectl get node [root@k8s-master01 .kube]# kubectl get node NAME STATUS ROLES AGE VERSION k8s-master01 NotReady master 13m v1.15.1 |
你会看到主节点已经就绪。
(5).其他2太主节点加入集群,
加入方式,复制初始化时生成的链接,在66.31 与 66.32 执行即可。
|
1 2 3 |
kubeadm join 192.168.66.100:6444 --token abcdef.0123456789abcdef \ --discovery-token-ca-cert-hash sha256:fe507d3fec5be688696843f43d4c14fd7200942ff04cf3820726e539ec530f5a \ --control-plane --certificate-key 6b150d74263066e8903d2bc8ca227ef19e5f77306ac3d798ff1a400537b84302 |
执行完成后,按提示,该创建的创建,该拷贝的拷贝(因为是管理节点,所以这些也是必要的)
|
1 2 3 |
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config |
其他2台加入完成后,查看节点状态
|
1 2 3 4 5 6 |
kubectl get node [root@k8s-master02 ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION k8s-master01 NotReady master 33m v1.15.1 k8s-master02 NotReady master 2m12s v1.15.1 k8s-master03 NotReady master 1m12s v1.15.1 |
(6).接下来修改 haproxy 配置文件(三个主节点都要操作)
|
1 2 3 4 5 6 7 |
vim /root/images/data/lb/etc/haproxy.cfg 将所有节点ip都补全 balance roundrobin server rancher01 192.168.66.30:6443 server rancher02 192.168.66.31:6443 server rancher03 192.168.66.32:6443 |
然后删除当前的ha-proxy容器 再重新启动容器 (三个master节点都要操作)
|
1 |
docker rm -f HAProxy-K8S && bash /root/images/data/lb/start-haproxy.sh |
(7).flannel网络部署(初始化节点操作)
如上所示,可以看到节点都已经加入进来了,但是状态还是NotReady
我们在上面已经导入了flannel的镜像,并且已经有了flannel.yaml文件,这里直接执行即可(yaml文件内容这里不解释,自己看我其他文章有介绍)
|
1 |
kubectl apply -f flannel.yaml |
|
1 2 |
#查看flannel是否在各个节点都已经启动 kubectl get node -n kube-system -o wide |
稍等一会,然后查看节点
|
1 |
kubectl get node |

其他
集群状态查看
|
1 2 3 4 5 6 7 8 9 |
#查看集群健康状况 kubectl -n kube-system exec etcd-k8s-master01 -- etcdctl \ --endpoints=https://192.168.66.30:2379 \ --ca-file=/etc/kubernetes/pki/etcd/ca.crt \ --cert-file=/etc/kubernetes/pki/etcd/server.crt \ --key-file=/etc/kubernetes/pki/etcd/server.key cluster-health kubectl get endpoints kube-controller-manager --namespace=kube-system -o yaml #查看kubeconfig 集群状态 kubectl get endpoints kube-scheduler --namespace=kube-system -o yaml #查看scheduleer集群状态 |

如果你运行 kubectl get node 第三次就卡住
你需要修改 .kube/config
|
1 2 3 |
#vvip 将:server: https://192.168.66.100:6444 修改为你自己本机ip + 6443端口 server: https://192.168.66.30:6443 |
原因:因为目前你执行命令,走的是ipvs,然后分发请求到其他节点,请求与返回需要时间,比较慢。这里你可以改回你自己的本机ip就不会有这种情况了。
- 本文固定链接: https://www.yoyoask.com/?p=2539
- 转载请注明: shooter 于 SHOOTER 发表