1.Kubernetes基础组件有哪些,什么功能?
|
1 2 3 4 5 6 7 |
kube-apiserver #负责集群数据的交互与通信 kube-controller-manager #负责集群各个资源的管控,使其保持在预期的工作状态 kube-schduler #集群的资源调度中心 etcd #键值对数据库,负责存储k8s集群的重要数据 kube-proxy #负责调度,将pod调度到最优节点上。 kubelet #每个节点上运行的代理,确保容器处于运行状态且健康。会定期想master汇报资源使用情况。 |
2.一个Pod创建流程
|
1 |
可通过kubectl或yaml创建pod请求,详细如下: |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
第一步: kubectl 向api server 发起一个create pod 请求 第二步: api server接收到pod创建请求后,不会去直接创建pod,而是生成一个包含创建信息的yaml。 第三步: apiserver 将刚才的yaml信息写入etcd数据库。到此为止仅仅是在etcd中添加了一条记录, 还没有任何的实质性进展。 第四步: scheduler 查看 k8s api ,类似于通知机制。 首先判断:pod.spec.Node == null? 若为null,表示这个Pod请求是新来的,需要创建;因此先进行调度计算,找到最“闲”的node。 然后将信息在etcd数据库中更新分配结果:pod.spec.Node = nodeA (设置一个具体的节点) ps:同样上述操作的各种信息也要写到etcd数据库中中。 第五步: kubelet 通过监测etcd数据库(即不停地看etcd中的记录),发现api server 中有了个新的Node; 如果这条记录中的Node与自己的编号相同(即这个Pod由scheduler分配给自己了); 则调用node中的docker api,创建container。 |
3.网络选型需要注意什么?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
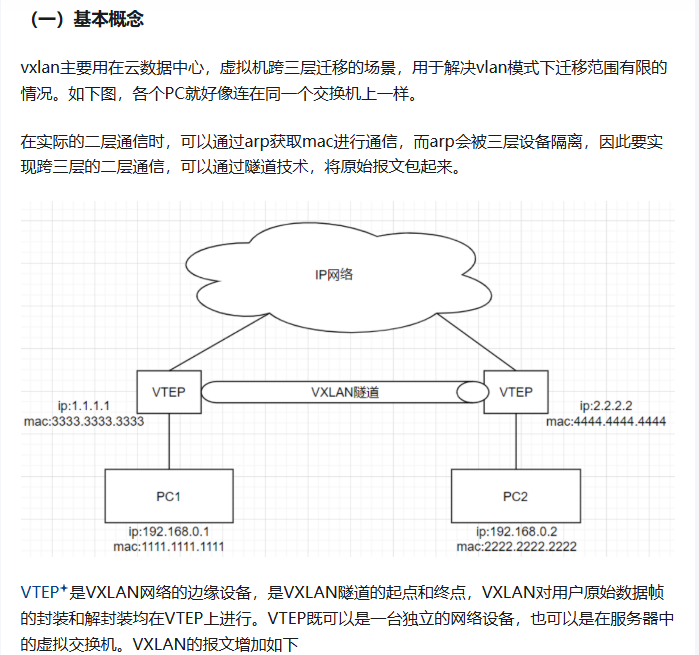
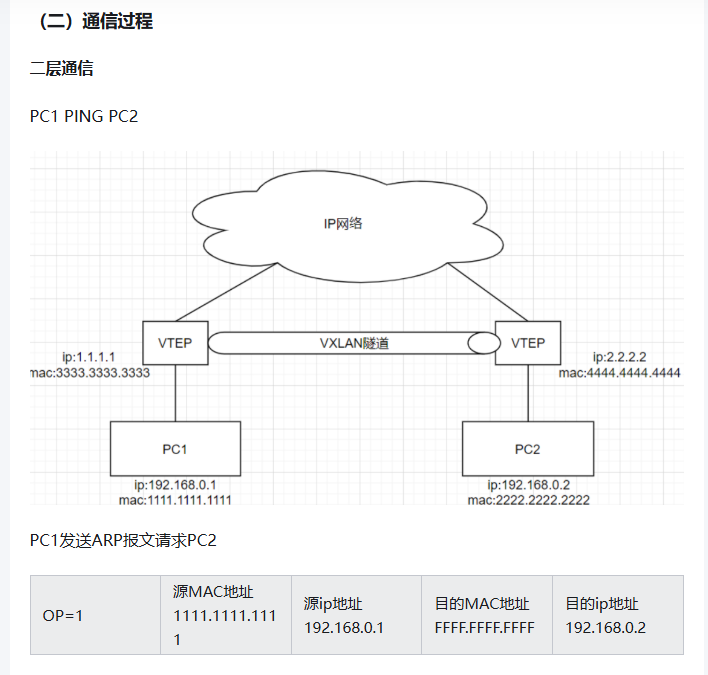
1.需要注意pod跨node的通信 2.网络性能 3.网络插件成熟度 4.网络策略 (最常用的应该是flannel和calico) calico网络模式 1)IPIP 把一个IP数据包又套在一个IP包里,即把IP层封装到IP层的一个 tunnel,它的作用其实基本上就相当于一个基于IP层的网桥,一般来说,普通的网桥是基于mac层的,根本不需要IP,而这个ipip则是通过两端的路由做一个tunnel,把两个本来不通的网络通过点对点连接起来; calico以ipip模式部署完毕后,node上会有一个tunl0的网卡设备,这是ipip做隧道封装用的,也是一种overlay模式的网络。当我们把节点下线,calico容器都停止后,这个设备依然还在,执行 rmmodipip命令可以将它删除。 2)BGP 边界网关协议(BorderGateway Protocol, BGP)是互联网上一个核心的去中心化的自治路由协议。它通过维护IP路由表或‘前缀’表来实现自治系统(AS)之间的可达性,属于矢量路由协议。BGP不使用传统的内部网关协议(IGP)的指标,而是基于路径、网络策略或规则集来决定路由。因此,它更适合被称为矢量性协议,而不是路由协议,通俗的说就是将接入到机房的多条线路(如电信、联通、移动等)融合为一体,实现多线单IP; BGP 机房的优点:服务器只需要设置一个IP地址,最佳访问路由是由网络上的骨干路由器根据路由跳数与其它技术指标来确定的,不会占用服务器的任何系统; 官方提供的calico.yaml模板里,默认打开了ip-ip功能,该功能会在node上创建一个设备tunl0,容器的网络数据会经过该设备被封装一个ip头再转发。这里,calico.yaml中通过修改calico-node的环境变量:CALICO_IPV4POOL_IPIP来实现ipip功能的开关:默认是Always,表示开启;Off表示关闭ipip。 Flannel的三种工作模式 1、UDP UDP是 Flannel 项目最早支持的一种方式,却也是性能最差的一种方式,这个模式目前已经被弃用。不过,Flannel 之所以最先选择 UDP 模式,就是因为这种模式是最直接、也是最容易理解的容器跨主网络实现。 2、VXLAN 原理: 通过虚拟可扩展局域网(VXLAN)技术,在物理网络之上创建覆盖网络(Overlay Network)。Flannel将容器流量封装在UDP数据包中(默认端口8472),通过隧道在主机间传输。 特点: 跨三层网络:适用于节点分布在多个子网的场景。 兼容性好:对底层网络要求低,适合复杂环境。 性能开销:因数据包封装/解封装,性能略低于host-gw,但可通过DirectRouting优化(同子网节点间直接路由,避免VXLAN封装)。 3、host-gw 利用主机的路由表直接转发流量,无需封装。每个节点充当相邻容器子网的网关,通过静态路由规则将目标容器IP的流量导向对应主机。 特点: 高性能:无封装开销,延迟低、吞吐量高。 网络限制:要求所有节点处于同一二层网络(直接可达),否则路由不可达。 配置简单:依赖静态路由,无需特殊网络设备。 (一)二三层网络区分 处于同一子网时进行二层通信,属于不同子网时是三层通信 如果源 IP 与目的 IP 处于一个子网,直接将包通过交换机发出去。 如果源 IP 与目的 IP 不处于一个子网,就交给路由器去处理。 (二)二层通信 PC1和PC2在同一个网段,PC1 ping PC2 PC1首先查看自己的ARP缓存表,确定其中是否包含有PC2对应的ARP表项。如果找到了对应的MAC地址,则PC1直接利用ARP表中的MAC地址,对IP数据包进行帧封装,并将数据包发送给主机B。 (四)三层通信 1、PC1和PC3不在同一个网段,PC1 ping PC3 2、PC1发现PC3和自己不在同一个网段,决定将报文发给默认网关192.168.1.10 3、PC1通过ARP找到默认网关的MAC地址 4、PC1源 MAC 地址与网关 MAC 地址封装在数据链路层头部,又将源 IP 地址和目的 IP 地址(注意这里千万不要以为填写的是默认网关的 IP 地址,从始至终这个数据包的两个 IP 地址都是不变的,只有 MAC 地址在不断变化)封装在网络层头部,然后发包。 5、交换机 1收到数据包后,发现目标 MAC 地址是 4444.4444.4444,转发给路由器 6、数据包来到了路由器 ,发现其目标 IP 地址是 192.168.2.1,查看其路由表,匹配端口号,获取192.168.2.1的MAC地址,将其从端口发出 7、交换机 3 收到了数据包,匹配MAC地址,从端口把数据包发出去。 8、PC3最终收到了对应的数据包。 |
VXLAN
4.Etcd用的什么算法,简单解释下
|
1 |
raft算法 强一致性 同一时间只能有一个leader,所有的操作都在leader上。 |
5.Pod中pending状态,是什么原因产生的?pod出现问题,排查思路
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
pending原因 1.可能是节点资源不足 2.不满足 nodeSelector 与 affinity 3.Node 存在 Pod 没有容忍的污点 4.kube-scheduler 未正常运行 5.镜像不存在 排查思路 kubectl describe pod 查看具体信息 到相应node上查看具体日志 |
6. pod的状态
|
1 2 3 4 5 |
Pending 等待中 Running 运行中 Succeeded 正常终止 Failed 异常停止 Unkonwn 未知状态 |
7.请回答Kubernetes发布策略(4种)
|
1 2 3 4 5 6 7 |
1.重建更新(Recreate)—停止旧版本部署新版本 2.滚动更新(rolling-update)—一个接一个地以滚动更新方式发布新版本 3.蓝绿更新—新版本与旧版本一起存在,然后切换流量 4.灰度更新(canary—将新版本面向一部分用户发布,然后继续全量发布 |
8.手写raft
9.你们监控用的什么?怎么利用普罗米修斯监控pod信息、Kubernetes的状态?如果你来设计相关的监控如何落地?
|
1 2 3 4 5 6 7 8 |
答: promethues-opreator pod 的metrics信息已经集成到的kubelet,直接用cAdvisor提供的metrics接口获取到所有容器相关的性能指标数据。然后使用自定义模板 通过grafana展示。(grafana上有许多优秀的模板) 当前使用的是promethues-opreator,如果集群过大可以考虑使用thanos高可用。 https://i4t.com/4136.html |
10. 如果利用Kubernetes实现滚动更新,怎么配置文件机制?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
deployment strategy RollingUpdatek ubectl rolling-update命令一键完成,更新实际上就是替换镜像版本,有以下几种方式进行更新: ① 修改deployment文件进行更新,pod执行过程是等待新的pod启动完成,在进行销毁旧的pod,这样就完成了集群的更新工作,创建和更新的时候记得加上--record ,--record的作用是将当前命令记录到 revision 记录中,这样我们就可以知道每个 revison 对应的是哪个配置文件。 ② 直接修改deployment进行更新镜像,需要直接编辑edit deployment 不太推荐 ③ 使用kubectl set命令进行替换镜像 回滚 rollout #查看版本号 kubectl rollout history deployment nginx-deployment 回退:--to-revision 如果不加这个参数则回退到上一个版本 kubectl rollout undo deployment nginx-deployment --to-revision=1 滚动更新:参考 https://blog.csdn.net/yunweimao/article/details/106894189 https://zhuanlan.zhihu.com/p/90282741 |
11.StatefulSet是怎么实现滚动更新的?
|
1 |
多个pod时,会按照顺序(序列号)滚动更新,每一个 Pod 都正常运行时才会继续处理下一个 Pod。 |
12.Kubectl exec实现的原理是什么?
|
1 2 3 |
首先会读取config文件 ,生成GET/POST请求 去访问apiserver apiserver会向kubelet发起连接 |
13.如何实现schedule水平扩展?
|
1 |
scheduler 只能有一个leader ,一般有三个节点就够。 |
14为什么k8s要用声明式?
|
1 2 3 4 5 6 |
命令式 和 声明式 区别 对于命令式请求(比如,kubectl replace ): 一次只能处理一个写请求,否则会有产生冲突的可能 (替换更新)。 对于声明式请求(比如,kubectl apply ) : 一次能处理多个写操作,并且具备 Merge 能力 (增量更新)。 只需描述期望状态就行,剩下的交给k8s。 |
15. 容器的驱逐时间是多少?由什么决定的?
|
1 2 3 |
默认驱逐时间是5min,可修改,是由kube-controller-manager的pod-eviction-timeout控制的。 node资源不足时也会发生驱逐,是按照qos等级来驱逐的。 |
16.节点的NotReady是什么导致的?NotReady会导致什么问题?
|
1 2 3 4 5 |
1. kubelet异常 不能和apiserver通信 2. 网络组件异常 notready时间过长pod会被驱逐到其他节点 |
17.Api-Server到etcd怎么保证事件不丢失?
18.就基本的k8s架构问题,遇到问题怎么处理?
19.有了解过QoS么?怎么实现的?
|
1 2 3 4 5 6 7 8 9 |
qos三种 Guaranteed, Burstable, and Best-Effort,它们的QoS级别依次递减。 Guaranteed 如果Pod中所有Container的所有Resource的limit和request都相等且不为0,则这个Pod的QoS Class就是Guaranteed。 Best-Effort 如果Pod中所有容器的所有Resource的request和limit都没有赋值,则这个Pod的QoS Class就是Best-Effort. Burstable 除了符合Guaranteed和Best-Effort的场景,其他场景的Pod QoS Class都属于Burstable。 node资源不足时会按qos级别驱逐pod。 最先驱逐的是Best-Effort ,重要组件一定要设置limit和request. |
20.详细叙述Kube-Proxy的原理
|
1 2 3 4 5 6 7 8 9 10 |
监听 API server 中 service 和 endpoint 的变化情况,并通过 iptables 等来为服务配置负载均衡 kube-proxy的作用主要是负责service的实现 service另外一个重要作用是,一个服务后端的Pods可能会随着生存灭亡而发生IP的改变,service的出现,给服务提供了一个固定的IP,而无视后端Endpoint的变化。 kube-proxy 模式: userspace 已弃用: iptables 大规模下会有性能问题 且不支持会话保持 ipvs |
21.K8s的Pause容器有什么用?是否可用去掉?
|
1 2 3 4 5 6 7 8 9 10 |
为pod中的多个容器提供共享网络空间,实现pod里容器间的通信。 主要有两个职责: 是pod里其他容器共享Linux namespace的基础 扮演PID 1的角色,负责处理僵尸进程 k8s的service和ep是如何关联和相互影响的 |
22.K8s的Serivce和EndPoint是如何管理和互相影响的?
|
1 2 3 4 5 |
service中有selector时才会创建endpoints. kube-proxy 会监视 Kubernetes 控制节点对 Service 对象和 Endpoints 对象的添加和移除。 只要服务中的pod集合发生更改,endpoints就会被更新 |
23.StatefulSets和Operator的区别是什么?
|
1 2 3 |
StatefulSet是为了解决有状态服务的。 opertator用来扩展k8s api,自定义crd。 |
原文出处 传送门
|
1 |
QoS学习: https://blog.csdn.net/qq_24794401/article/details/103368917 |
- 本文固定链接: https://www.yoyoask.com/?p=5171
- 转载请注明: shooter 于 SHOOTER 发表
这个作者貌似有点懒,什么都没有留下。