|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
rabbitMQ是什么?他的运行原理是怎样的?他有什么用?他都有哪几种集群模式? a.普通模式:默认的集群模式。 b.镜像模式:把需要的队列做成镜像队列,存在于多个节点,属于RabbitMQ的HA方案 1.普通模式:默认的集群模式 RabbitMQ集群中节点包括内存节点、磁盘节点。内存节点就是将所有数据放在内存,磁盘节点将数据放在磁盘上。如果在投递消息时,打开了消息的持久化,那么即使是内存节点,数据还是安全的放在磁盘。那么内存节点的性能只能体现在资源管理上,比如增加或删除队列(queue),虚拟主机(vrtual hosts),交换机(exchange)等,发送和接受message速度同磁盘节点一样。一个集群至少要有一个磁盘节点。一个rabbitmq集群中可以共享user,vhost,exchange等,所有的数据和状态都是必须在所有节点上复制的,对于queue根据集群模式不同,应该有不同的表现。在集群模式下只要有任何一个节点能够工作,RabbitMQ集群对外就能提供服务。 默认的集群模式,queue(队列)创建之后,如果没有其它policy(条限),则queue(队列)就会按照普通模式集群。对于queue来说,消息实体只存在于其中一个节点,A、B两个节点仅有相同的元数据,即队列结构,但队列的元数据仅保存有一份,即创建该队列的rabbitmq节点(A节点),当A节点宕机,你可以去其B节点查看,./rabbitmqctl list_queues发现该队列已经丢失,但声明的exchange还存在。 当消息进入A节点的queue中后,consumer(用户)从B节点拉取时,RabbitMQ会临时在A、B间进行消息传输,把A中的消息实体取出并经过B发送给consumer(用户),所以consumer(用户)应平均的连接每一个节点,从中取消息。该模式存在一个问题就是当A节点故障后,B节点无法取到A节点中还未消费的消息实体。如果做了队列持久化或消息持久化,那么得等A节点恢复,然后才可被消费,并且在A节点恢复之前其它节点不能再创建A节点已经创建过的持久队列;如果没有持久化的话,消息就会失丢。这种模式更适合非持久化队列,只有该队列是非持久的,客户端才能重新连接到集群里的其他节点,并重新创建队列。假如该队列是持久化的,那么唯一办法是将故障节点恢复起来。 为什么RabbitMQ不将队列复制到集群里每个节点呢?这与它的集群的设计本意相冲突,集群的设计目的就是增加更多节点时,能线性的增加性能(CPU、内存)和容量(内存、磁盘)。当然RabbitMQ新版本集群也支持队列复制(有个选项可以配置)。比如在有五个节点的集群里,可以指定某个队列的内容在2个节点上进行存储,从而在性能与高可用性之间取得一个平衡(应该就是指镜像模式) 说完概念性的东西,我们就进入实战搭建吧。 |
#注意:本人是用docker来做的,基本都大同小异,有差异的就是docker镜像系统都是最小安装,里面很多依赖包都没有。
思路:先装好一个容器(centos7),然后把整个配置好的容器docker打包提交成镜像,然后再以这个配置好的镜像再启动2例容器,然后配置这三个容器,达到集群效果,其实和开了多个虚拟机是一样的。就不用每台机器都配置一下了,懒
废话不说,开始
1.启动这个容器
|
1 2 3 |
#8888是给ssh客户端连接用的,映射到了22端口 #15672是配置完后访问rabbitmq客户端用的 #docker run -tid -p 8888:22 -p 15672:15672 --privileged=true [centos镜像id] centos01 |
2.安装相关依赖(由于docker镜像centos系统都是很小的,很多软件和插件都没有)
安装这些依赖或软件前请 yum update一下,否则后面有你受的(各种低版本版本不被识别,编译erlang的时候气死你)
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#1.安装openssh 查看ssh是否安装 rpm -qa | grep ssh 注:若没安装SSH则可输入: yum install openssh-server安装。 启动SSH服务。 输入命令:service sshd restart重启SSH服务。 命令:service sshd start 启动服务 | 命令:service sshd stop停止服务 重启后可输入:netstat -antp | grep sshd查看是否启动22端口(可略)。 如何设置SSH服务为开机启动? 输入命令:chkconfig sshd on即可。 注:若是chkconfig sshd off则禁止SSH开机启动。 |

2.关闭防火墙,如果你一定要开着防火墙,请把rabbitmq所依赖的这几个端口【 5672|25672|15672 】和ssh远程连接端口【22】打开
|
1 2 3 4 5 6 7 8 |
#关闭防火墙: systemctl stop firewalld.service #开放端口: firewall-cmd --zone=public --add-port=5672/tcp --permanent && firewall-cmd --zone=public --add-port=15672/tcp --permanent && firewall-cmd --reload #关闭开机启动: systemctl disable firewalld.service |
3.安装依赖环境(安装前请先执行yum update 否则后面有你受的)
|
1 |
yum install -y wget make gcc gcc-c++ kernel-devel m4 ncurses-devel openssl-devel unixODBC-devel net-tools libxslt xmlto nc rsync zip unzip openssl-devel kernel-devel m4 |
4.安装erlang
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
mkdir /opt/erlang cd /opt/erlang wget http://erlang.org/download/otp_src_19.3.tar.gz tar -xvzf otp_src_19.3.tar.gz cd otp_src_19.3 #设置环境 ./configure --prefix=/opt/erlang/opt_19.3 --with-ssl -enable-threads -enable-smmp-support -enable-kernel-poll --enable-hipe --without-javac make && make install |
【错误区】
这里在检查环境的时候,很多时候会报
|
1 2 3 4 5 6 7 8 |
crypto : No usable OpenSSL found ssh : No usable OpenSSL found ssl : No usable OpenSSL found #注意,这里提示找不到Openssl ,原因有2个 1.你确实没有安装OpenSSL这个依赖 2.你安装的OpenSSL版本不对,不能被识别 #另外,我在centos8上一直没有成功,无论我装什么版本的OpenSSL都不被识别 #只要你安装依赖前yum update过应该都没有问题,注意前面的那些步骤,不要给自己找事 |
|
1 2 |
#设置目录软链接,下面配置环境变量要用 ln -s /opt/erlang/opt_19.3 /usr/local/erlang |
配置下环境变量 vim /etc/profile
|
1 2 3 4 5 6 7 |
ERLANG_HOME=/usr/local/erlang #下来这句是给后面安装的rabitmq准备的 RABBITMQ_HOME=/usr/local/rabbitmq-server PATH=$PATH:$ERLANG_HOME/bin:$RABBITMQ_HOME/sbin export PATH USER LOGNAME MAIL HOSTNAME HISTSIZE HISTCONTROL ERLANG_HOME RABBITMQ_HOME |
source /etc/profile 刷新使环境变量生效

复制.erlang.cookie到其它集群机器上(注意,只有安装了rabbitmq才会生成erlang.cookie,所以这一步放到后面操作,因为目前我们就一台机器,另外因为我的镜像配置完后,其他容器依赖这个镜像启动,所以他们的cookie都一样,所以我也不用复制)
|
1 |
scp /root/.erlang.cookie root@10.10.1.X:/root/ |
5.安装rabbitmq-server
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
[命令] mkdir /opt/rabbitmq cd /opt/rabbitmq wget http://www.rabbitmq.com/releases/rabbitmq-server/v3.6.8/rabbitmq-server-3.6.8.tar.xz mv rabbitmq-server-3.6.8.tar.xz rabbitmq-server-src-3.6.8.tar.xz tar xvJf rabbitmq-server-src-3.6.8.tar.xz mv rabbitmq-server-3.6.8 rabbitmq-server-src-3.6.8 cd rabbitmq-server-src-3.6.8 make make install RMQ_ERLAPP_DIR=/opt/rabbitmq/rabbitmq-server-3.6.8 #设置目录链接,对应上头环境变量里的目录 ln -s /opt/rabbitmq/rabbitmq-server-3.6.8 /usr/local/rabbitmq-server |
安装完成 启动rabbitmq
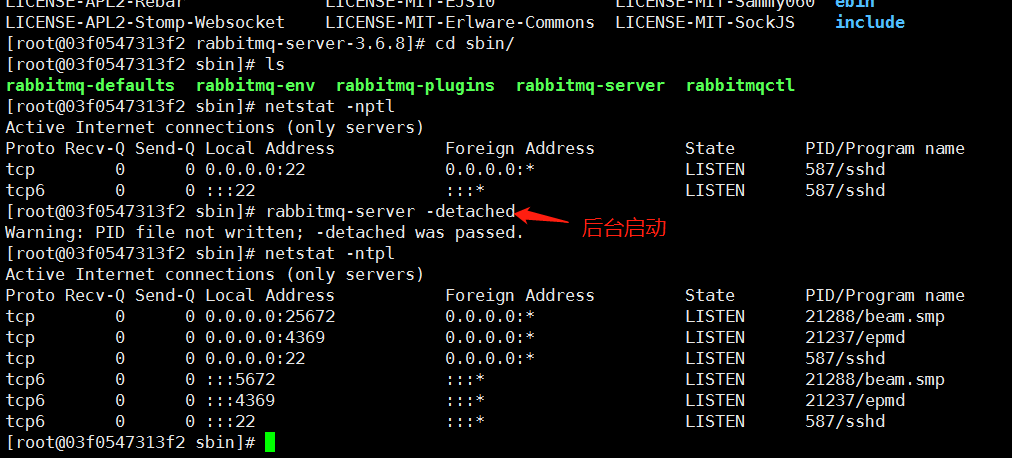
|
1 2 3 4 5 6 7 8 9 10 |
rabbitmq常用命令 rabbitmqctl stop #停止 rabbitmq-server restart #启动 rabbitmq-server -detached #后台运行 rabbitmq-server start #前台运行 #启用常用插件,web客户端管理啊什么的包括管理插件、web-stomp插件等 mkdir /etc/rabbitmq #这句必须执行,否则下面的插件启动不知道往哪写入 cd /opt/rabbitmq/rabbitmq-server-3.6.8/sbin/ rabbitmq-plugins enable rabbitmq_management #开启Web管理界面 开启后就可以看到15672端口 就可以访问rabbitmq的web端界面 |
设置RabbitMQ开机启动
设置开机启动(个人感觉网上那个rabbitmq-server个脚本好像写的有问题,配置后并不能让其正常启动,个人采用下列方式配置开机启动)
|
1 2 3 4 5 6 7 8 9 |
#1.创建一个启动脚本 vim /usr/local/rabbitmq-server/sbin/start.sh #写入这些内容 #!/bin/bash #这里我刷新环境变量使之生效,因为那个erlong很多次重启后他不生效,刷新环境变量后才生效可用,可能是我镜像的原因 source /etc/profile /usr/local/rabbitmq-server/sbin/./rabbitmq-server -detached |

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
给脚本增加可执行权限 chmod +x /usr/local/rabbitmq-server/sbin/start.sh 编辑 /etc/rc.d/rc.local 增加 #!/bin/bash # THIS FILE IS ADDED FOR COMPATIBILITY PURPOSES # # It is highly advisable to create own systemd services or udev rules # to run scripts during boot instead of using this file. # # In contrast to previous versions due to parallel execution during boot # this script will NOT be run after all other services. # # Please note that you must run 'chmod +x /etc/rc.d/rc.local' to ensure # that this script will be executed during boot. touch /var/lock/subsys/local /opt/rabbitmq/rabbitmq-server/sbin/start.sh |
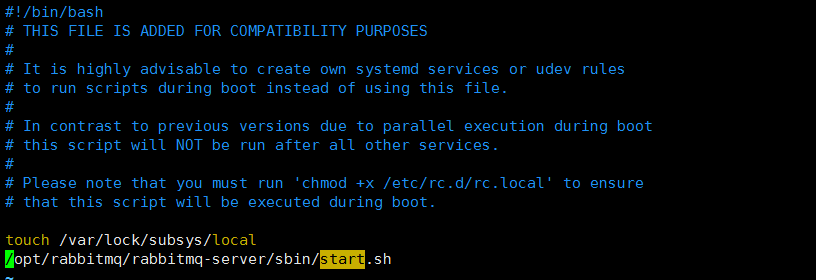
|
1 2 3 |
给rc.local增加可执行权限 chmod+x /etc/rc.d/rc.local 重启 shutdown -r now |
到此单机配置rabbitMQ就配置完成,接下来提交这个容器为新的镜像(提交打包镜像不属于本节内容), 然后以这个新镜像,启动三个容器,开始集群配置
|
1 2 3 4 5 |
[命令] 之所以加/usr/sbin/init是因为在docker中通过systemctl 启动服务的时候总是报Failed to get D-Bus connection: Operation not permitted 这样的错误提示。 docker run -itd -p 7777:22 15671:15672 --name centos01 --privileged=true registry.cn-shanghai.aliyuncs.com/shooer/by_docker_shooter:rabbitMQ /usr/sbin/init docker run -itd -p 8888:22 15672:15672 --name centos02 --privileged=true registry.cn-shanghai.aliyuncs.com/shooer/by_docker_shooter:rabbitMQ /usr/sbin/init docker run -itd -p 9999:22 15673:15672 --name centos03 --privileged=true registry.cn-shanghai.aliyuncs.com/shooer/by_docker_shooter:rabbitMQ /usr/sbin/init |

|
1 |
开始配置这三台机器的集群 |
1.配置host文件
|
1 2 3 4 5 6 7 8 9 10 |
#我没有修改主机名称,我是在docker启动的,不好改,怕出问题,如果你要修改就在对应机器上执行以下语句改下主机名称 hostnamectl set-hostname rabbitmqnode1 hostnamectl set-hostname rabbitmqnode2 hostnamectl set-hostname rabbitmqnode3 #我的不需要修改就保持了原名,我的host文件是 172.17.0.2 4c030c450ee7 172.17.0.4 03f0547313f2 172.17.0.3 38f1b2e0c0da #注意:三台机器的配置文件都需要一致,复制上头这三条配置下其他2台机器 |
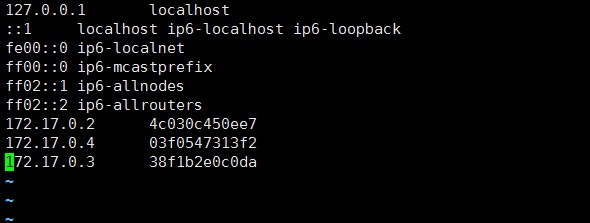
2.下来配置 RabbitMQ添加集群:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
1.先停止掉其他2台节点的rabbitmq rabbitmqctl stop_app 2.然后把第一个rabbitmq节点的rabbitmq拷贝覆盖到其他两个节点,让三个节点保持一致。 #注意:配置前请保证 .erlang.cookie 三台机器一致,不一致请用命令先拷贝(拷贝覆盖前请先停止要拷贝到机器的rabbitmq,拷过去启动下看是否正常) scp /root/.erlang.cookie root@10.10.1.X:/root/ #3.rabbitmqnode1:RabbitMQ开启状态下 启动node2 和 node3的rabbitMQ rabbitmq-server -detached #后台运行 #4.启动172.17.0.4的rabbitMQ加入集群 a.先执行 rabbitmqctl stop_app 关闭rabbitmq b.再执行:rabbitmqctl join_cluster rabbit@4c030c450ee7 c.开启: service rabbitmq-server restart | rabbitmq-server -detached #5.启动172.17.0.3的rabbitMQ加入集群 a.先执行 rabbitmqctl stop_app 关闭rabbitmq b.再执行:rabbitmqctl join_cluster rabbit@4c030c450ee7 c.开启: service rabbitmq-server restart | rabbitmq-server -detached 这一块来回关闭开启。正常 |
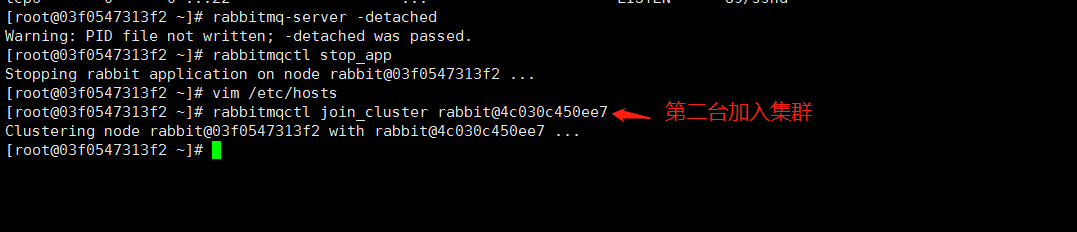

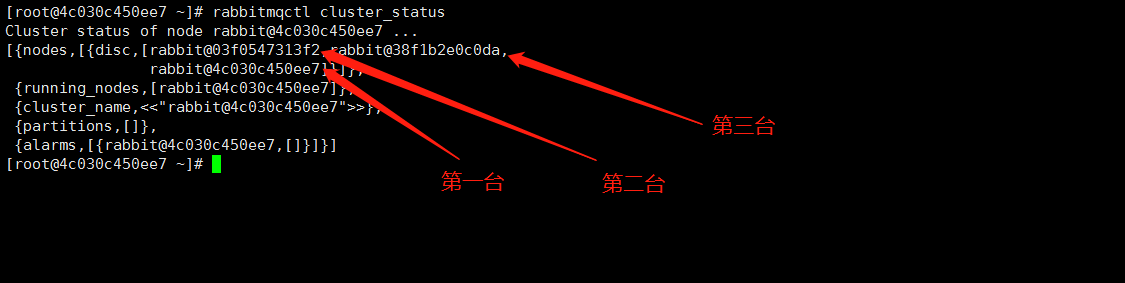
查看集群是否成功
|
1 |
rabbitmqctl cluster_status |
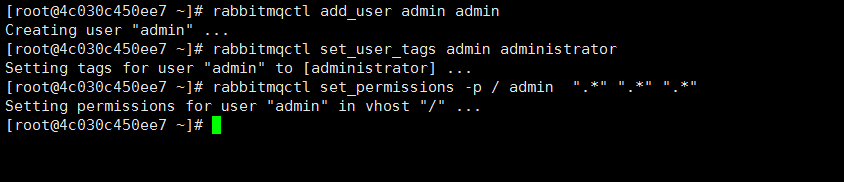
创建用户
|
1 2 3 4 5 6 7 8 |
// 启用rabbitmq_management # rabbitmq-plugins enable rabbitmq_management // 创建管理用户 # rabbitmqctl add_user admin admin // 将admin 用户赋予管理员角色 # rabbitmqctl set_user_tags admin administrator // 授予“管理员”用户修改、写入和读取所有vhost的权限。 # rabbitmqctl set_permissions -p / admin ".*" ".*" ".*" |
访问客户端界面(ip:15672)
|
1 |
一个rabbitmq集群中可以共享user(用户),vhost,exchange等,所有的数据和状态都是必须在所有节点上复制的,对于queue根据集群模式不同,应该有不同的表现。在集群模式下只要有任何一个节点能够工作,RabbitMQ集群对外就能提供服务 |
到此已经成功配置集群 对于RabbitMQ如何在开发语言中建立连接并使用 推荐看这个大神的文章 请点击这里跳转 写的太好了
个人目前应用场景:每天上游公司会推送一批百度关键词排名查询的信息,大约有100多万条,这个肯定不能直接一下插入100W条到数据库,mysql会死掉,目前解决办法是用rabbitMQ做缓冲,先入队列,然后再从队列取出来入库。
关于RabbitMQ持久化
|
1 |
我们先在客户端添加几条队列消息 |
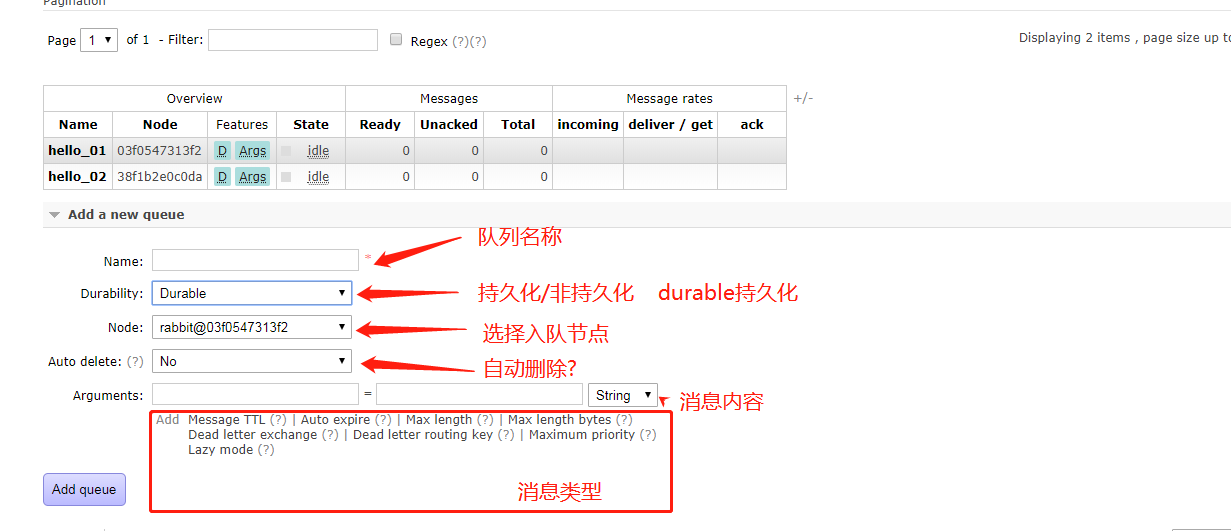
然后使用 rabbitmqctl list_queues #列出队列

如果你是持久化添加,那么重启之后数据依然在
如果你是非持久化添加的队列,那么重启之后你会丢失这个队列
|
1 2 3 4 |
在代码中 1.队列持久化需要在声明队列时添加参数 durable=True,这样在rabbitmq崩溃时也能保存队列 2.仅仅使用durable=True ,只能持久化队列,不能持久化消息 3.消息持久化需要在消息生成时,添加参数 properties=pika.BasicProperties(delivery_mode=2) |
关于队列持久化,可以参考这篇文章理解 点击跳转,写的很棒。
补充#
|
1 2 3 4 5 6 7 |
#单节点(单台机器)的rabbitMQ修改disk space路径 vim /usr/local/rabbitmq-server/sbin/rabbitmq-defaults 修改:MNESIA_BASE=${SYS_PREFIX}/var/lib/rabbitmq/mnesia 为MNESIA_BASE=${SYS_PREFIX}你的路径地址 #然后把当前系统默认路径下的所有文件挪到你自建的路径下 mv /var/lib/rabbitmq/mnesia/* 你的路径地址 然后重启RabbitMQ即可 |
关于RabbitMQ配置文件
如果不配置配置文件也好像没什么事情,但是日志会报
/etc/rabbitmq/rabbitmq.config(not found)
所以还是加上吧
找到你的编译目录,在目录下有个文件 rabbitmq.config.example 复制到 /etc/rabbitmq 下 更改名称为 rabbitmq.config 然后重新启动rabbitmq即可
|
1 2 3 4 |
cp /opt/rabbitmq/rabbitmq-server-3.6.8/rabbitmq.config.example /etc/rabbitmq/ mv rabbitmq.config.example rabbitmq.config service rabbitmq-server restart |
然后这个not found 就不会有了
- 本文固定链接: https://www.yoyoask.com/?p=316
- 转载请注明: shooter 于 SHOOTER 发表