shell正则表达式与开发语言不同,他分为基础正则和扩展正则
1.基础正则
注:正则是包含匹配,即只要包含某个要匹配的元素就会找出来
*:匹配前一个字符0次或任意多次
|
1 2 3 |
例: grep "a*" text.txt #匹配包含a字符的所有内容,注意这样写是有问题的,会匹配出所有内容,为什么呢,因为他是匹配的0个或者任意多次,就是有或者没有都会匹配到,所以匹配的是所有内容 grep "aa*" text.txt #这样写才是匹配包含a字母的内容 |
. :匹配除了换行符意外的任意字符
|
1 2 |
例: grep "b." text.txt #匹配包含字母b后任意一个字符的内容 |
^ :匹配行首,例如:^shooter 会匹配以 shooter开头的行
|
1 2 |
例: grep "^good" text.txt #匹配以good开头的行 |
$ :匹配行尾, 例如:shooter$ 会匹配以 shooter结尾的行
|
1 2 3 4 5 |
例: grep "shooter&" text.txt 扩展: 匹配以s开始,r结尾 grep "^s.*r$" text.txt #匹配以s开头 r结尾 中间匹配任意字符. *表示匹配任意字符多次 |

[] :匹配中括号内指定的任意一个字符,只匹配一个字符
|
1 2 3 4 5 |
例:[abcd] 匹配任意一个元音字母,只匹配一个字符 [0-9] 匹配任意一位数字 [a-z][0-9] 匹配任意一个元音字母和任意一个数字构成的2位字符 grep "[0-9][a-z]" text.txt |
[^]:匹配除了中括号内所有内容以外的内容(取反)
|
1 2 3 |
例: [^0-9] 匹配任意一位非数字字符 [^a-z] 匹配任意一位非小写字母字符 grep "[^a-z]" text.txt |
\ :转义符 用于将特殊符号的含义取消,回归字符层面意思
|
1 2 3 4 |
例: 匹配以s开头 以 . 结尾 grep "^s.*\.$" test.txt #因为.在匹配符中有特殊含义所以使用\转义他为普通字符,再进行匹配 |
\{n\} : 表示其前面的字符恰好出现n次。
|
1 2 3 4 5 |
例:\是转义符的意思上面说过了,目的是把{}转成普通支付 #匹配四位任意数字 grep "[0-9]\{4\}" text.txt #匹配手机号码 grep "^[1][3-8][0-9]\{9\}" text.txt |
\{n,\}:表示其前面的字符出现不小于n次
|
1 2 3 |
例: #匹配2位以上的数字 grep "\{2,\}" text.txt |
\{n,m\} : 表示其前面的字符最少出现n次,最多出现m次
|
1 2 3 |
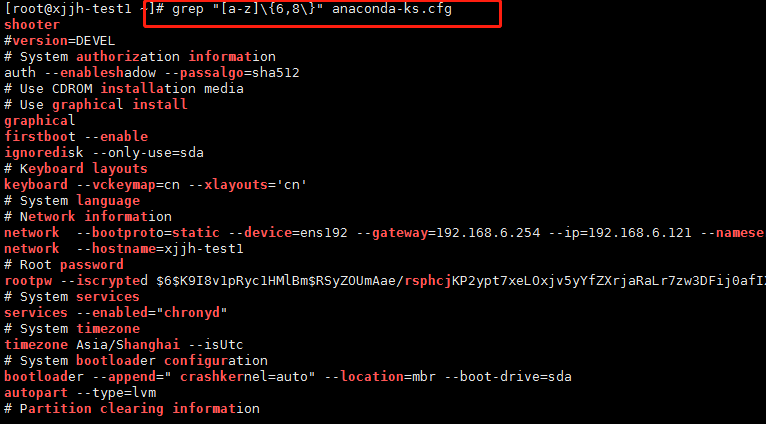
例: #匹配6到8位小写字母 grep "[a-z]\{6,8\}" text.txt |
扩展正则(基本用的较少)
注: 扩展正则grep是无法识别的,必须使用egrep 或者grep -E选项
+ : 前一个字符匹配1次,或者任意多次
|
1 2 3 4 5 |
例: grep -E "s+" text.txt or egrep "s+" text.txt #例如匹配 google grep -E "go+gle" text #匹配到的会是 gogle google 或者 gooogle 当然有继续多的o也能匹配,前提是必须前面有o ,不像* 会匹配前方0-任意 |
? : 前一个字符匹配0次或者1次
|
1 2 3 4 5 6 7 8 9 10 |
例: grep -E "s?" text.txt 扩展知识: + 和 ? 号相当于把 0-1 和 1 - n 隔开了 例如匹配 google grep -E "go?gle" text.txt # 只会匹配到gogle 或者 google |
| : 匹配有两个或者多个分支选择
|
1 2 3 4 5 |
例: #匹配was 或者 hit 或者 shooter grep -E "was|hit|shooter" text.txt #既会匹配was也会匹配包含hit也会匹配包含shooter的 |
() :匹配其整体为一个字符,即模式单元,可以理解为由多个单个字符组成的大字符
|
1 2 |
例: #(dog)+ 会匹配 dog,dogdog,dogdogdog 等,因为被小括号包含为一个整体 但是 "hello (word|liming)" 会匹配 hello word 和 hello liming |
- 本文固定链接: https://www.yoyoask.com/?p=922
- 转载请注明: shooter 于 SHOOTER 发表
这个作者貌似有点懒,什么都没有留下。