1. 主观造成主从节点间binlog的丢失
MGR故障模拟1
如下是搭建完成后的MGR集群,目前集群处于完全正常的状态中。

|
1 2 3 4 5 6 7 |
#执行如下操作,主观造成主从节点间binlog的丢失 use shooter; SET SQL_LOG_BIN=0; #设置下面操作不记录到binlog日志中 INSERT INTO book VALUES (4, 'shooter'); SET SQL_LOG_BIN=1; #开启记录 select @@server_uuid AS this_server_uuid,t.* from performance_schema.global_status t where t.variable_name = 'group_replication_primary_member' |
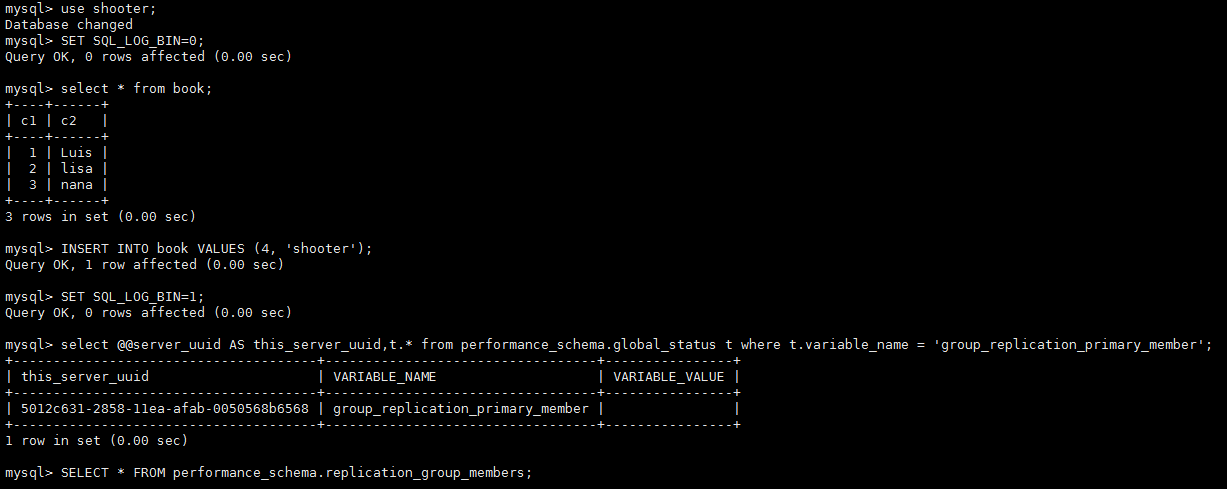
然后我们在主节点上删除刚才添加的这条数据。
|
1 |
delete from book where c1=4; |
在主节点上对于对于从节点丢失的数据操作,GTID无法找到对应的数据,组复制会立马熄火
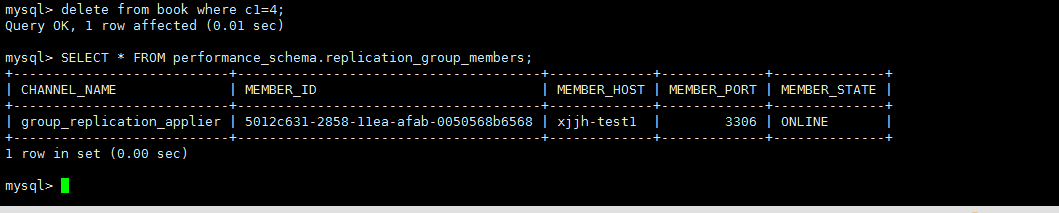
另外2个非写入节点出现错误


查看错误日志:
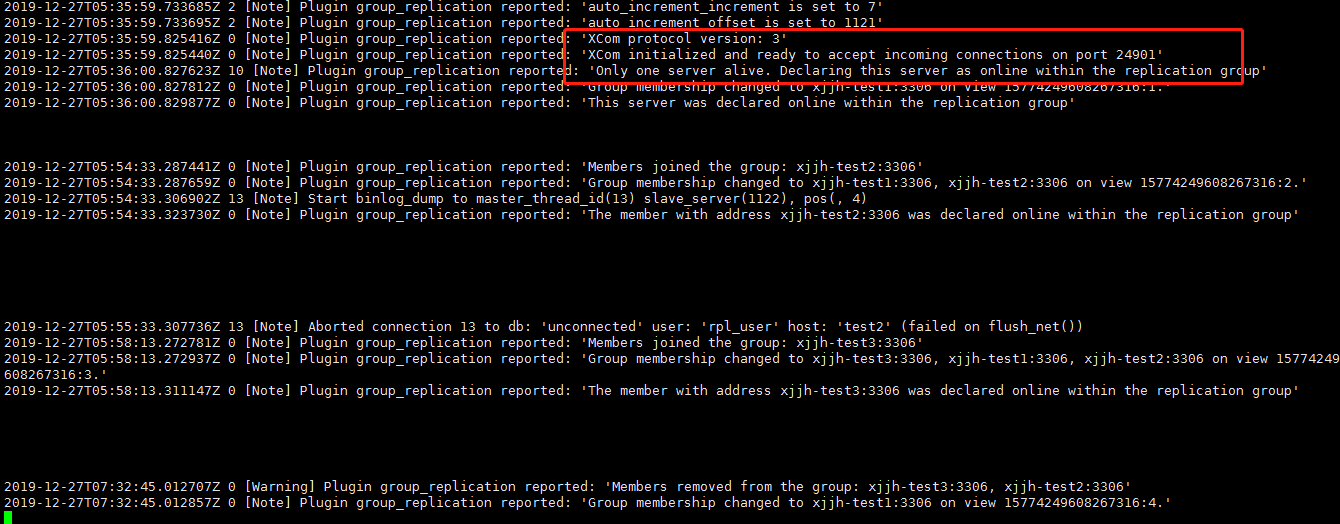
查看当前存货的节点node1状况
|
1 2 |
select * from performance_schema.replication_group_member_stats\G show global variables like '%gtid%'; |
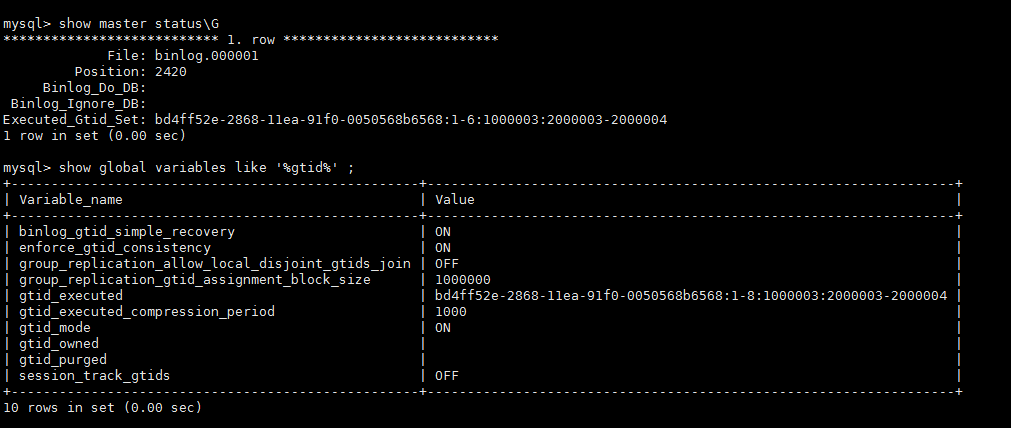
上面我们通过制造数据不一致,binlog过期造成node2和node3一直处于RECOVERING状态无法同步直到放弃同步
通过跳过GTID方式解决
修改gtid_purged值
在坏掉的节点上执行如下操作
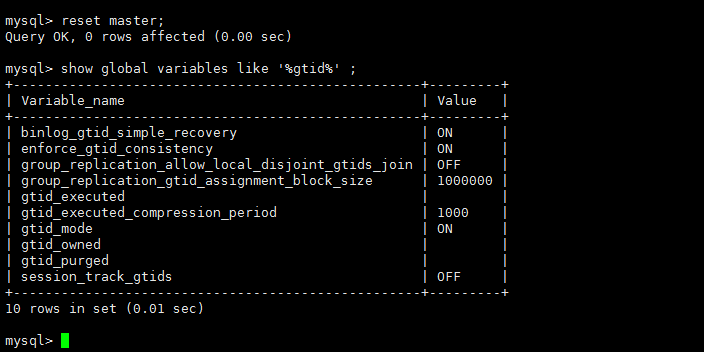
先重置,清除node2和node3节点的gtid_purged值
|
1 2 |
reset master; show global variables like '%gtid%'; |
|
1 2 |
官方文档描述gtid_purged值是基于最旧binlog日志文件的Previous_gtids_log_event值,即上面node1的: bd4ff52e-2868-11ea-91f0-0050568b6568:1-8:1000003:2000003-2000004 |
根据node1的gtid_purged ,更改node2和node3的gtid_purged,使其从该gtid_purged开始复制,即不再复制主库之前执行过已经丢失binlog的gtid,这种跳过事务同步的方法存在数据不一致的隐患。
下来在node2和node3上面操作
|
1 2 3 4 5 6 7 8 9 |
stop group_replication; #因为当前是1-6,要跳过当前到7 set global gtid_purged='bd4ff52e-2868-11ea-91f0-0050568b6568:1-8:1000003:2000003-2000004'; #重新加入组 CHANGE MASTER TO MASTER_USER='rpl_user',MASTER_PASSWORD='123456' FOR CHANNEL 'group_replication_recovery'; #查看当前的gtid_purged show global variables like '%gtid%'; #启动 START GROUP_REPLICATION; |
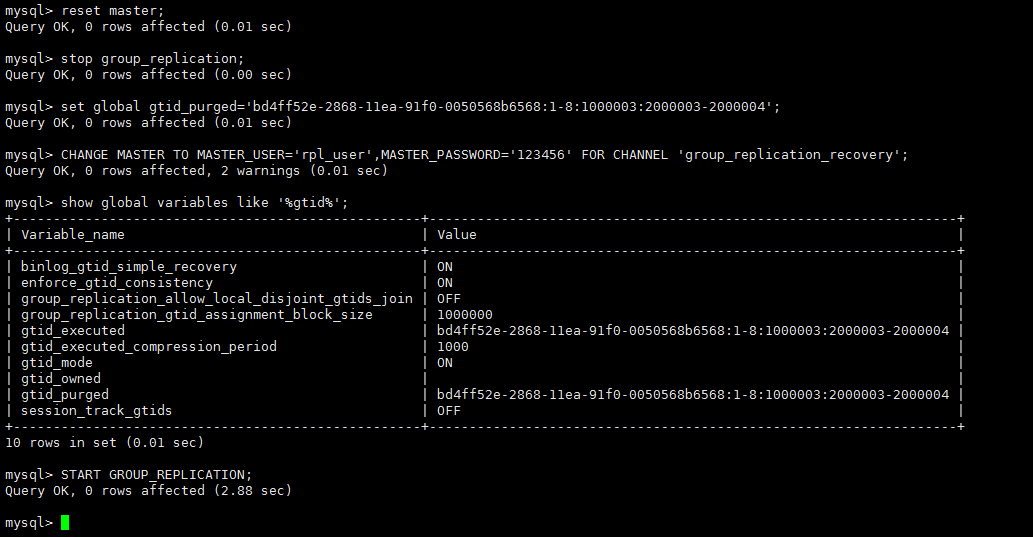
查看节点当前状态
|
1 |
SELECT * FROM performance_schema.replication_group_members; |

虽然节点启动了,但是当前机器的数据与主节点是不一致的。
数据不一致的解决
先从其他机器拷贝一份数据同步到这台宕机的数据库(否则你启动了,虽然连接到组了但是你和当前主primary数据是不一致的,因为你宕机的时候主primary数据并没有停止继续写入,当用户执行删除,你当前跳过的这台机器上,没有primary那条数据,后面用户轮循删除到这台机器,就出错的,组就会自动退出),日志会报如下错误
|
1 2 3 4 5 6 7 8 9 |
#日志错误如下 [ERROR]Slave SQL for channel 'group_replication_applier': Could not execute Delete_rows event on table shooter.book; Can't find record in 't1', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log FIRST, end_log_pos 153, Error_code: 1032 [Warning] Slave: Can't find record in 't1' Error_code: 1032 [ERROR] Error running query, slave SQL thread aborted. Fix the problem, and restart the slave SQL thread with "SLAVE START". We stopped at log 'FIRST' position 180 [ERROR] Plugin group_replication reported: 'The applier thread execution was aborted. Unable to process more transactions, this member will now leave the group.' [ERROR] Plugin group_replication reported: 'Fatal error during execution on the Applier process of Group Replication. The server will now leave the group.' [ERROR] Plugin group_replication reported: 'The server was automatically set into read only mode after an error was detected.' [Note] Plugin group_replication reported: 'The group replication applier thread was killed' [Note] Plugin group_replication reported: 'Group membership changed: This member has left the group.' |
为了避免数据不一致的错误,在恢复宕机节点前,先把主机器数据写入暂停一下(可能要在半夜搞,因为和这个时候没有用户访问),然后把主数据全部同步到当前宕机这台。使之保持一致。然后再恢复宕机这台的复制组。
然后在宕机恢复后的机器执行如下操作。
|
1 2 3 4 5 6 7 8 |
#查看当前状态 reset master; show global variables like '%gtid%' ; set global gtid_purged='bd4ff52e-2868-11ea-91f0-0050568b6568:1-26:1000015';(从主机器或者其他机器获取) CHANGE MASTER TO MASTER_USER='rpl_user',MASTER_PASSWORD='123456' FOR CHANNEL 'group_replication_recovery'; SET SESSION binlog_format = 'ROW'; SET GLOBAL binlog_format = 'ROW'; START GROUP_REPLICATION; |
然后查看当前节点状态

2.模拟主宕机(多主模式)
关闭node1mysql服务
查看另外2台node2,node3节点


现在在node3,node2随便一台写入数据(我这里写入node3)
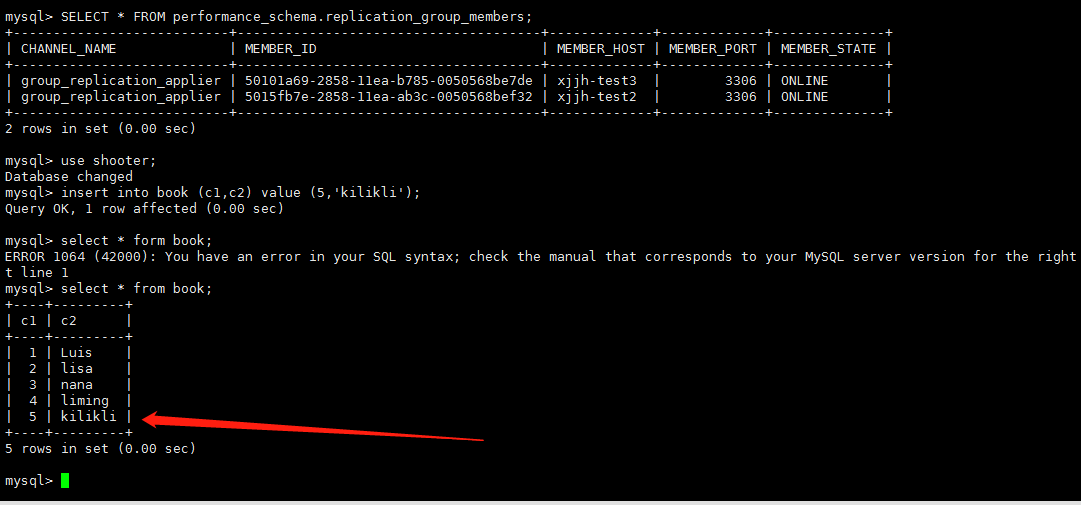
查看node2是否同步过去了

现在启动node1(模拟node1恢复了)
|
1 2 3 4 |
登入启动MGR组 START GROUP_REPLICATION; |

只有他自己在线,这是为什么呢,因为他宕机后他就不再是主master,他就成了从。所以要把他加入复制组
|
1 2 3 4 5 6 7 8 |
reset master; set global gtid_purged='bd4ff52e-2868-11ea-91f0-0050568b6568:1-8:1000003:2000003-2000004'; CHANGE MASTER TO MASTER_USER='rpl_user',MASTER_PASSWORD='123456' FOR CHANNEL 'group_replication_recovery'; SET SESSION binlog_format = 'ROW'; SET GLOBAL binlog_format = 'ROW'; SET GLOBAL group_replication_bootstrap_group=ON; START GROUP_REPLICATION; SET GLOBAL group_replication_bootstrap_group=OFF; |
启动后发现数据和其他机器不一致怎么办
|
1 2 3 4 5 6 7 8 9 10 |
从其他机器备份一份数据过来,然后导入这台机器的数据库,导入数据前你要先清空当前节点的gtid_purged,然后用souce xxxx.sql导入你的备份 reset master; set global gtid_purged='bd4ff52e-2868-11ea-91f0-0050568b6568:1-8'; CHANGE MASTER TO MASTER_USER='rpl_user',MASTER_PASSWORD='123456' FOR CHANNEL 'group_replication_recovery'; SET SESSION binlog_format = 'ROW'; SET GLOBAL binlog_format = 'ROW'; SET GLOBAL group_replication_bootstrap_group=ON; START GROUP_REPLICATION; SET GLOBAL group_replication_bootstrap_group=OFF; |
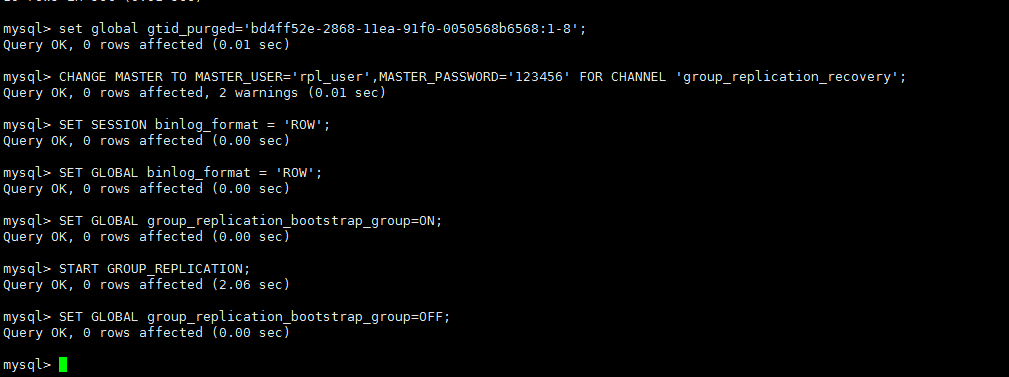
查看节点
1.模拟主宕机(单主模式 )
1.查看当前单主集群状态
|
1 |
SELECT MEMBER_ID,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,IF(global_status.VARIABLE_NAME IS NOT NULL,'PRIMARY','SECONDARY') AS MEMBER_ROLE FROM performance_schema.replication_group_members LEFT JOIN performance_schema.global_status ON global_status.VARIABLE_NAME = 'group_replication_primary_member' AND global_status.VARIABLE_VALUE = replication_group_members.MEMBER_ID; |

模拟主宕机
|
1 2 3 |
#在123机器kill掉mysql pkill mysql |

查看另外2台机器当前状态
可以看到121这台机器成了新的主机primary

模拟主机器一直在写入数据,我们在121这台主机器插入数据
|
1 2 3 |
insert into book (c1,c2) value (17,'panda01'); insert into book (c1,c2) value (18,'panda02'); insert into book (c1,c2) value (19,'panda03'); |

查看122这台从机器
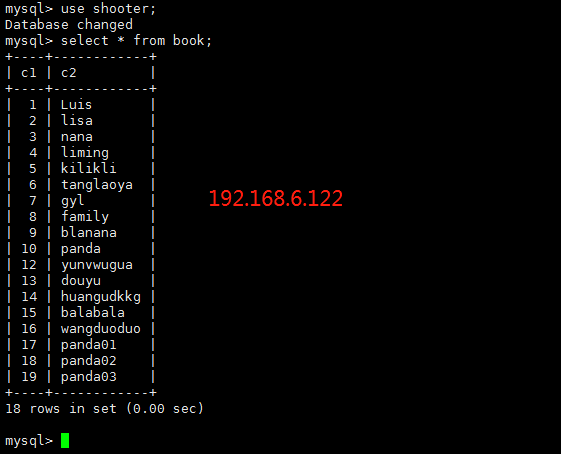
现在启动刚才宕机那台mysql,
这时候重启这台宕掉的机器,并且加入到复制组当中,显然他已经不是主机器了
我们当前不做任何配置,也不和现在的主机通过备份文件同步数据,直接启动复制组,让他自主同步数据,如果使用先前的配置他是否可以正常启动,并且同步数据,那么表示这样是ok的
|
1 2 3 |
SET SESSION binlog_format = 'ROW'; SET GLOBAL binlog_format = 'ROW'; START GROUP_REPLICATION; |

查看组状态
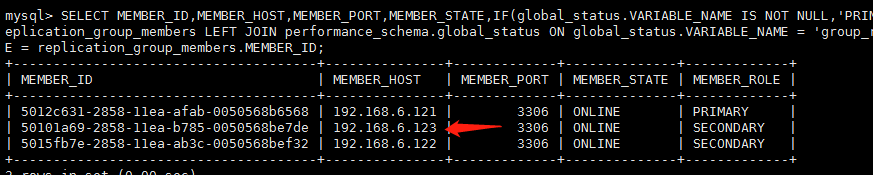
查看刚才插入的数据是否同步过来了
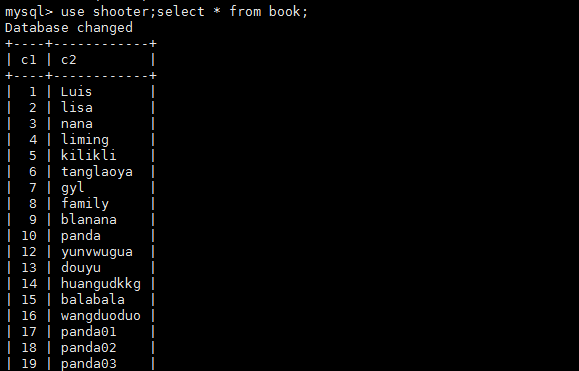
总结:MGR一定要按顺序关闭,按顺序开启,关闭顺序 从->主 ,启动顺序 主->从 否则会出现错误。切记切记
总结:MGR重启节点一定要按顺序,比如,如果重启主节点,一定要先关闭其他从节点,否则主节点关闭后,其他节点筛选出新的主节点,当你在启动主节点就无法连接上了,你这时候只能把刚才重启的主节点按宕机的办法处理后。才可以启动
总结:一般情况下,节点重启,或者组重启,都不会影响数据同步,即使在重启的当时主节点发生数据变动,其他节点重启后也会执行同步主节点数据同步,使数据保持一致。
总结:MGR
恢复节点加入组的坑爹错误 节点状态一直RECOVERING,然后节点退出组
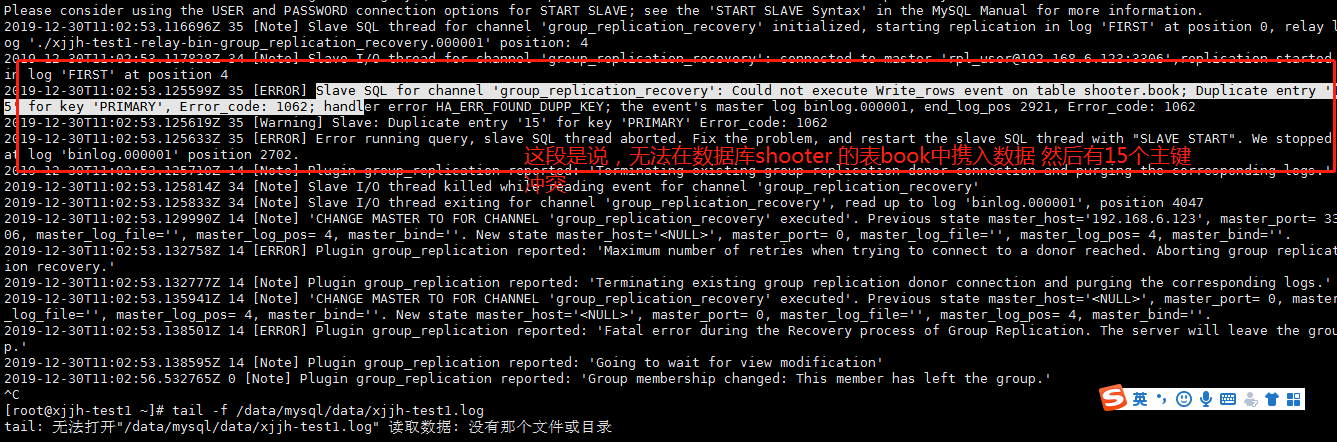
意思是说你开始从组复制数据,但是你的shooter数据库的表 book 无法写入,然后有主键重复 15次,大概是这个意思。我们按照这个错误继续向下分析
我们现在去刚宕机启动的这台机器看一下,这个数据库是否可写。

果然不可写,看来在单主模式下只能支持2个可写文件 ,即A -B交替为主。具体后面再写。
- 本文固定链接: https://www.yoyoask.com/?p=1226
- 转载请注明: shooter 于 SHOOTER 发表