1.grep 提取行命令
|
1 2 3 4 5 6 |
grep [选项] 文件名 例: 我们要在某个文件里找 某个字符 grep "ad" text.txt #查找文件中是否包含ad,再在包含ad的内容中找出so grep "ad" text.txt | grep "so" |

1.cut 提取列命令
|
1 2 3 4 |
cut [选项] [文件名] -f [列号] #提取第几列 -d [分隔符] 按照指定分隔符分割列 -c [字符范围] 不依赖分隔符来区分列,而是通过字符范围来进行字段提取。"n-" n表示数值,例:2- 表示第二个字符到行尾 n-m 表示第n个字符到第m个字符 |
|
1 2 |
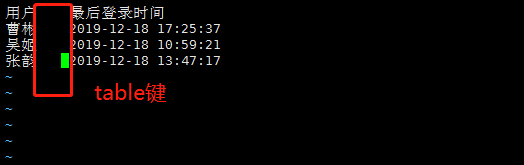
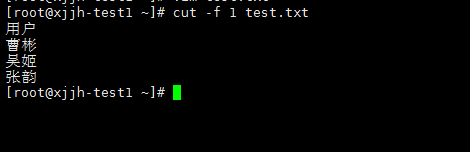
#cut提取第1列,用户名称 cut -f 1 test.txt |
|
1 2 3 |
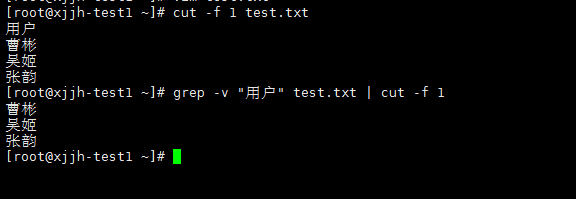
可以看到,连同标题一起取出来了,怎么办呢 #先grep 取反,再在返回结果中取第一列 grep -v "用户" test.txt | cut -f 1 |
|
1 2 |
grep "shooter" test.txt | cut -c 2- grep "shooter" test.txt | cut -c 2-4 |

|
1 2 |
#-d通常和-f配合使用,-d为以什么分割,-f取出分割后第几列 cut -d ":" -f 1,2 /etc/passwd |
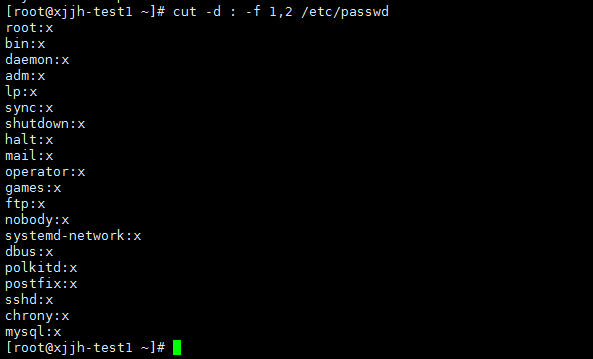
cut命令是不能以 空格来分割的 这个主意,如果想以空格来分割 ,请使用awk命令
printf 格式化输出
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
printf '输出类型/输出格式' 输出内容 输出类型: %ns: 输出字符串。n是数字指代输出几个字符 %ni: 输出整数。n是数字指代输出几个数字 %m.nf :输出浮点数,m和n是数字指代输出的整数位数和小数位数,如%8.2f代表共输出8位数,其中后2位是小数,前6位是整数 (如果你在awk中要进行运算,就必须输出格式调整为数字,字符串是无法进行运算的) 输出格式: \a :输出警告声音 \b :输出退格键,也就是Backspace键 \f : 清除屏幕 \n : 换行 \r : 回车,也就是enter键 \t :水平输出退格键 也就是tab键 \v : 垂直输出退格键 也就是tab键 |
printf ‘%s’ $(cat test.txt) #注意prinf后面只支持命令的结果输出,他是没有办法读取文件的

printf 是要我们手工来调整输出格式的(我们的这个文档里只有2列所有如下调整)
|
1 2 |
#输出一个字符串 用tab键隔开\t 结尾换行 (为了输出看到方便中间用空格隔开) printf '%s\t %s\t \n' $(cat test.txt) |
没办法 awk 只识别printf命令,其他都不识别,你要想会awk 必须会printf
另外:printf 不识别管道符传递过来的值,如果想要识别必须写在$(cat test.txt|grep -v “用户) 必须这样写,printf只识别awk传递来的值,所以一般我们通过管道先把值传给awk,再由awk传递给printf
|
1 2 3 |
printf '%s\t %s\t \n' $(cat test.txt|grep -v "用户") #管道传递给awk awk传递给print(这块如果不懂,先往后看) df -h | awk '{print $4}' |
3.awk编程
awk基本使用
|
1 2 3 4 5 6 7 8 9 10 |
#awk支持print 和 printf 他们的区别在于,print会自动帮你结尾换行 printf 需要你写\n才会换行 awk '条件1{动作1} 条件2{动作2} ...' 文件名(如果你在单引号里要操作printf 记得格式使用双引号) 例: #$2 ,$6 代表位置参数变量 $2第二列,$6第六列 awk '{printf $2 "\t" $6 "\n"}' test.txt #当前这个表达式没有条件,只有动作 awk '{print $1"\t" $2"\t"}' test.txt #print输出 |
awk最常见的用法,提取列
|
1 |
df -h | awk '{print $4}' |
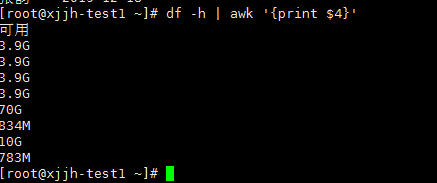
需求:我现在要提取跟分区的剩余空间数量,如果大于90%就要发邮件提醒管理员加磁盘了
|
1 |
df -h | grep "/dev/mapper/centos-root" | awk '{print $5}' | cut -d "%" -f 1 |

awk[条件]
|
1 2 3 4 5 6 |
条件: BEGIN :在awk程序一开始时,尚未读取任何数据前执行,begin后的动作只在程序开始时候执行一次(先处理再执行) END:在awk处理完所有数据,即将结束执行。END 后的动作只在程序结束时执行一次(最后执行,end用的不太多,begin用的较多) 例:awk支持多个条件和动作 awk 'BEGIN{print "你好啊"}{print $1}' test.txt |

关系运算符
|
1 2 3 4 5 6 7 8 |
> :大于 < :小于 >= :大于等于 <= :小于等于 == :判断两端是否相等 != : 不等于 A`B:判断字符串A中是否包含B表达式的子字符串 A!B:判断字符串A中是不是不包含B表达式的子字符串 |
|
1 2 3 |
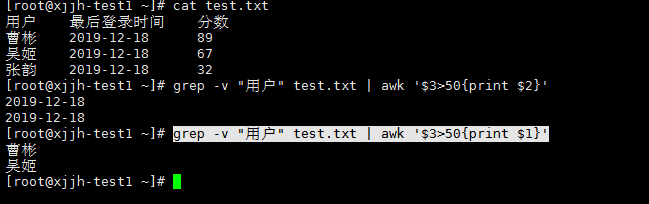
例:打印出分数大于50的学生名字 分数(第三列) 人名(第一列) grep -v "用户" test.txt | awk '$3>50{print $1}' grep -v "用户" test.txt | awk 'BEGIN $3>60 {print $3}' |
|
1 2 3 4 |
#A`B:判断字符串A中是否包含B表达式的子字符串 awk '$1 ~ /曹斌/ {print $3}' test.txt #如果在第一列找到了曹斌这个用户 就打印他的分数(第三列)(列查找) #A!B:判断字符串A中是不是不包含B表达式的子字符串 awk '/曹斌/ {print $3}' test.txt #如果这一列找到了曹斌,就打印他的分数(行及查找) |
awk内置变量
|
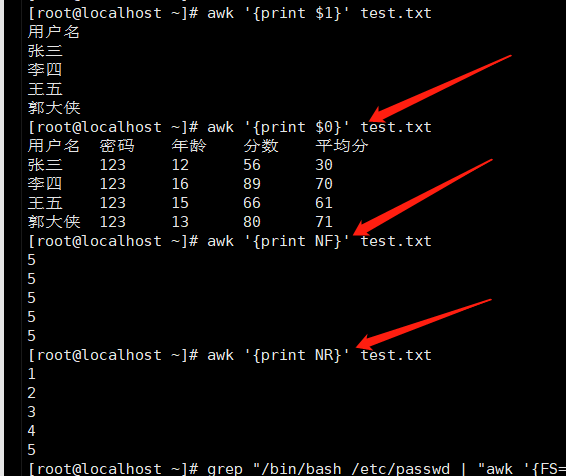
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
$0 :代表目前awk所读入的整行数据,我们已知awk是一行一行读入数据的,$0代表当前读入行的数据 $n :代表目前读入行的第n个字段 NF :当前行拥有的的字段(列)总数 NR :当前awk所处理的行,是总数据的第几行 FS :用户定义分隔符。awk默认分隔符是任何空格,如果需要使用其他分隔符如:,就需要FS变量定义 (下面这些用的少) ARGC:命令行参数个数 AEGV:命令行参数数组 FNR :当前文件种的当前记录数(输入文件的起始为1) OFMT: 数值的输出格式(默认为%6.g) OFS : 输出字段的分隔符(默认为空格) ORS :输出记录分隔符(默认为换行符) RS : 输入记录分隔符(默认为换行符) |

|
1 2 3 4 5 6 7 8 9 10 |
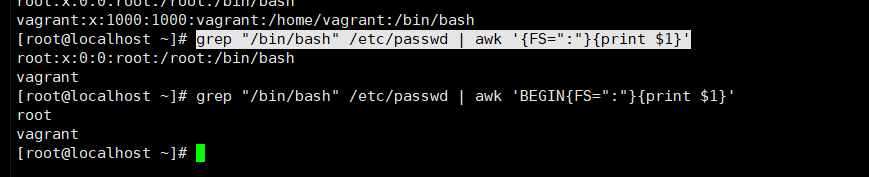
注意: grep "/bin/bash" /etc/passwd | awk '{FS=":"}{print $1}' 这里为什么读出来的没有用分隔符,分隔第一行呢,而是完整读出来了第一行 因为 (awk 是先读数据到awk,再去处理) awk 它会先把第一行数据都到awk里面 再用 {print $1} 来处理 ,换句话说,我已经把第一行数据读进来了赋给了$0 $1 ....等 ,里面了。我才看到你写的{FS=":"}分隔符是: 这个时候对于第一行数据已经来不及了,只能从第二行数据开始分隔,也就是说awk 他是先读入数据,后加载的分隔。所以分隔从第二行开始才生效。 怎么解决这个问题?对 BEGIN grep "/bin/bash" /etc/passwd | awk 'BEGIN{FS=":"}{print $1}' #记住了,手工指定分隔符之前一定要加BEGIN这样你的分隔符条件才会生效 |
|
1 |
grep "/bin/bash" /etc/passwd | awk 'BEGIN{FS=":"} $3>13{print $1}' |

|
1 |
grep "/bin/bash" /etc/passwd | awk 'BEGIN{FS=":"} {print $1"\t" $3"\t 行号:"NR"\t 字段数:"NF"\n"}' |

sed命令
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
send [选项] '动作' 操作文件名 选项: -n :一般sed命令会把所有数据都输出到屏幕,如果加入此选择,则只会把经过sed命令处理的行输出到屏幕上 -e :允许对输入数据应用多条sed命令编辑 -f :脚本文件名:从sed脚本中读入sed操作。和awk命令的-f类似 -r :在sed中支持扩展正则表达式 -i :用sed的修改结果直接修改读取数据的文件,而不是由屏幕输出 动作: a \ :追加,在当前行后添加一行或多行。添加多行时,除最后一行外,每行末尾都需要用"\"代表数据未完结 c \ :行替换,用c后面的字符串替换原数据行,替换多行时,除最后一行外,每行末尾需用"\"代表数据未完结 i \ :插入,在当期行前插入一行或多行。插入多行时,除最后一行外,每行末尾需要用"\"代表数据未完结 d :删除,删除指定行 p :打印输出指定行 s :字符串替换,用一个字符串替换另一个字符串,格式为:"行范围s/旧字符串/新字符串/g" (和vim中的替换几乎一样) |
1.打印输出第二行
|
1 |
sed -n '2p' test.txt |
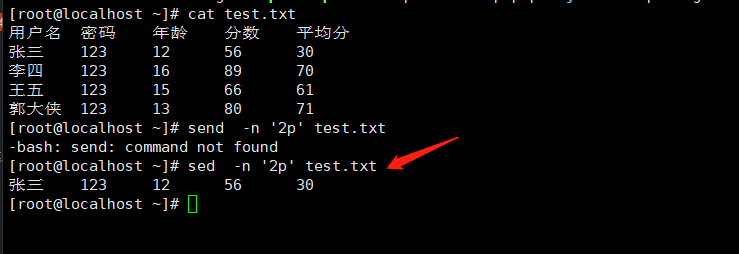
-i 是将你操作文件最后的结果写入文件,如果不加就只是动作删除,不写入文件
–e 加上-e可以执行多条动作,例如多条删除
2.在指定行之后追加一行
|
1 |
sed -i '2a 追加了这行' test.txt |
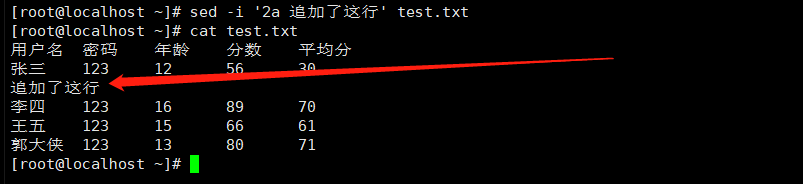
3.删除一行
|
1 |
sed -i '2,3d' test.txt |
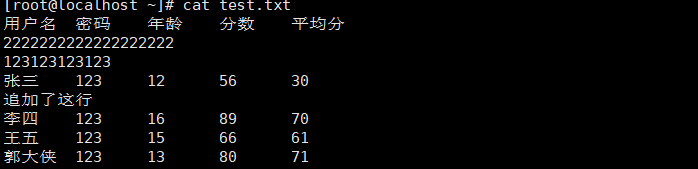
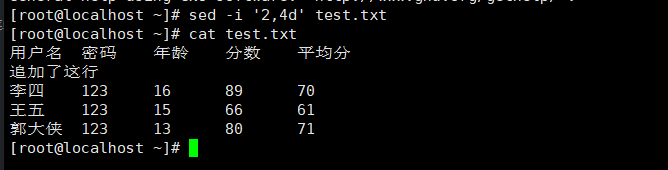
删除多行
|
1 |
sed -e '2d;3d;4d' test.txt |
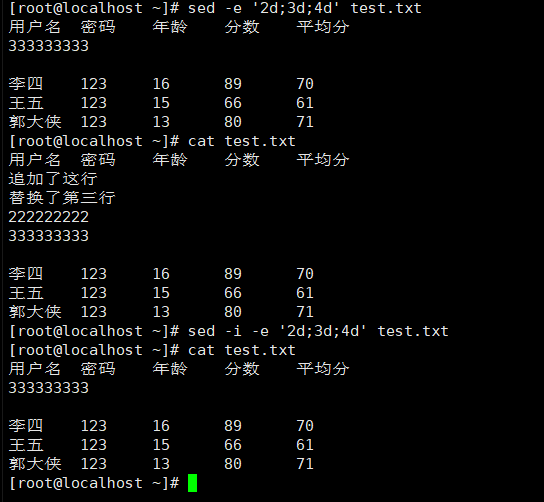
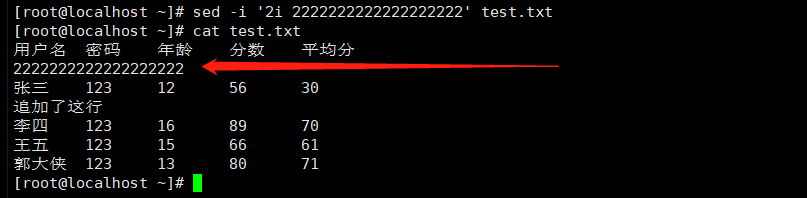
4.在第二行之前插入一行
|
1 |
sed -i '2i 2222222222222222222' test.txt |
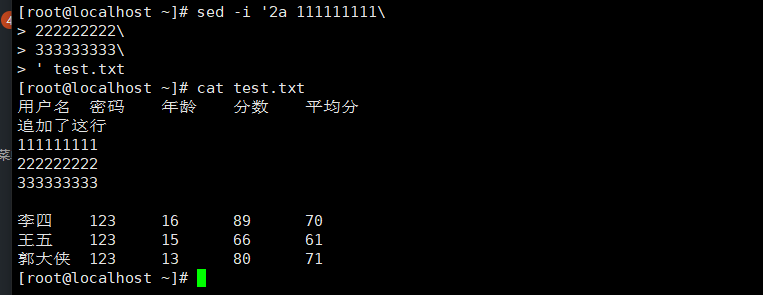
5.追加多行 \
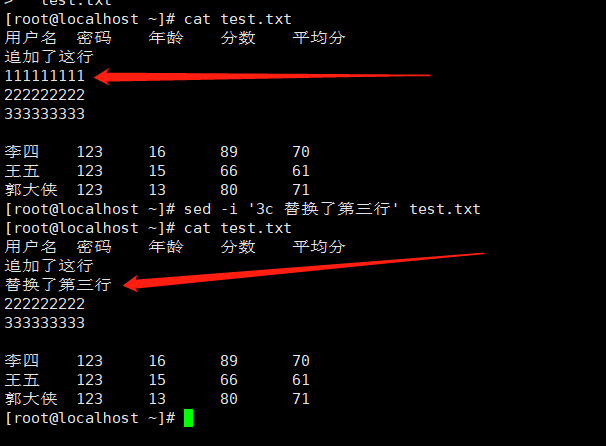
6.替换行
|
1 |
sed -i '3c 替换了第三行' test.txt |
7.单个字符串替换
|
1 2 3 4 5 6 7 8 |
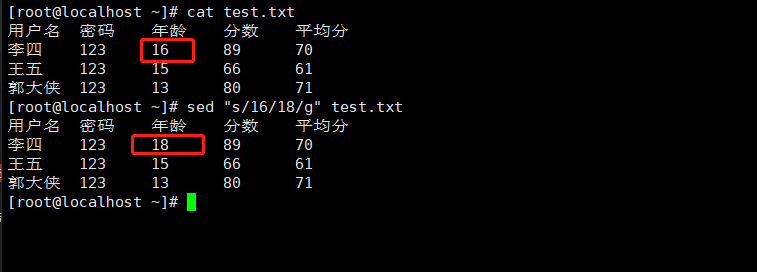
sed "行范围s/旧字符串/新字符串/g" test.txt (和vim中的替换类似) 如果不写行范围,就是替换整篇文档 sed "s/16/18/g" test.txt #替换第三行中的内容,并且写入文件 sed -i "3s/66/77/g" test.txt #替换多个动作 sed -i "3s/66/77/g ; 4s/35/45/g" test.txt |

8.行首加入#号
|
1 2 3 4 |
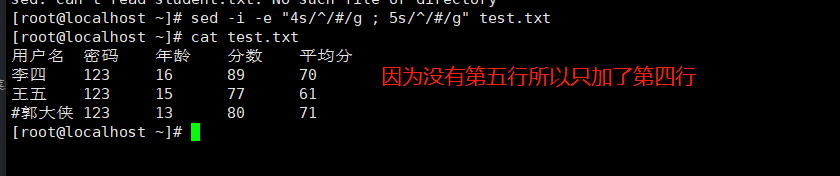
#和vim一样 sed -i "4s/^/#/g" test.txt #多个请使用 -e 选项 sed -i -e "4s/^/#/g ; 5s/^/#/g" test.txt |
Sed在匹配行 前 后 加入一行
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
a 追加内容 sed ‘/匹配词/a\要加入的内容’ example.file(将内容追加到匹配的目标行的下一行位置) i 插入内容 sed ‘/匹配词/i\要加入的内容’ example.file 将内容插入到匹配的行目标的上一行位置) 示例: #我要把文件的包含“shooter.com”这个关键词的行前或行后加入一行,内容为“mont.com” 1 #行前加 2 sed -i '/shooter.com/i\mont.com' the.conf.file 3 #行后加 4 sed -i '/shooter.com/a\mont.com' the.conf.file --------------------------------------------------- 1、删除指定行的上一行 sed -i -e :a -e '$!N;s/.*\n\(.*ServerName abc.com\)/\1/;ta' -e 'P;D' $file 2、删除指定字符串之间的内容 sed -i '/ServerName abc.com/,/\/VirtualHost/d' $filehttp://www.linuxso.com/shell/17542.html |
sort字符串处理命令
|
1 2 3 4 5 6 7 8 9 |
sort [选项] 文件名 选项: -f :忽略大小写 -b :忽略每行前面的空白部分 -n :以数值型进行排序,默认使用字符串类型排序 -r :反向排序 -u :删除重复行.就是uniq命令 -t :指定分隔符,默认是分隔符是制表符 |
默认按照每行开头第一个字符串来进行排序
|
1 |
sort /etc/passwd |
反向排序
|
1 |
sort -r /etc/passwd |
按指定分隔符的第三个字段来排序(起始和结束都按第三个字段)
|
1 |
sort -t ":" -k 3,3 /etc/passwd |
按数字来排序 -n
|
1 |
sort -n -t ":" -k 3,3 /etc/passwd |
uniq取消重复行命令
|
1 2 3 4 |
uniq [选项] test.txt 选项: -i 忽略大小写 uniq -i test.txt |
wc 统计命令
|
1 2 3 4 5 6 7 |
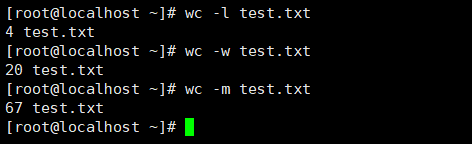
wc [选项] 文件名 选项 -l :只统计行数 -w : 只统计单词数 -m : 只统计字符数 |
- 本文固定链接: https://www.yoyoask.com/?p=957
- 转载请注明: shooter 于 SHOOTER 发表
这个作者貌似有点懒,什么都没有留下。